Prezados alunos,
Abaixo comento as questões de banco de dados, business intelligence e processo de negócio da prova de analista de sistemas do concurso do STM. A prova veio num nível bastante elevado, mas é sempre bom aprender com os erros. Temos dois recursos possíveis. Sem mais delongas, vamos aos comentários.
-
Ano: 2018 Banca: CESPE Órgão: STM Cargo: Analista de Sistemas Questão: 51 a 54
No contexto do desenvolvimento de sistemas de processamento de dados, julgue os itens a seguir, relativos ao gerenciamento de processos de negócio.
51 Além de buscarem medir, monitorar e controlar atividades e administrar o presente e o futuro do negócio, os processos de suporte entregam valor para outros processos, mas não o fazem diretamente para os clientes.
52 Para melhor compreender o processo e a organização, modelos AS-IS (estado atual) realizam avaliação inicial baseada em fatos documentados e validados; e modelos TO-BE (estado futuro) utilizam simulação para compreender as lacunas no processo atual que impedem a transição para o estado desejado.
53 No BPMN (Business Process Model and Notation), utiliza-se o modelo de uma piscina (pool) que contém uma ou mais raias (lanes), na(s) qual(is) é possível inserir diversos símbolos, como retângulos arredondados (para representar processos, atividades ou tarefas ou subprocessos), setas (para representar uma sequência de fluxo) e losangos (para, a partir de avaliação de determinada condição, representar caminhos alternativos ou paralelos).
54 A partir da redefinição dos processos e de suas respectivas atividades e tarefas, os custos associados à mudança dever-se-ão a fatores como resistência das pessoas às mudanças, interesses ocultos, conflitos de interesse e esforço na padronização de processos para aumentar a eficiência organizacional.
Comentário: Vamos comentar cada uma das alternativas acima.
- Ao analisar o valor da utilização de processo para melhoria do desempenho organizacional temos que identificar quais as atividades agregam valor e quais são desnecessárias e contribuem para aumentar o tempo, os custos, os erros e a insatisfação de clientes. A análise do valor classifica cada atividade de um processo em três tipos básicos:
- Adiciona valor ao cliente. Produz valor ou contribui para a satisfação do cliente.
- Adiciona valor ao negócio. Contribui para garantir o cumprimento de políticas ou regulamentações.
- Não adiciona valor. Atividade que não adiciona valor ao cliente nem ao negócio e deveria ser candidata à eliminação.
Esse é uma das classificações possíveis para os processos. Outra taxonomia divide os processos em primários ou finalísticos, de suporte e gerenciais.
Os processos gerencias são os processos estabelecidos para coordenar e controlar as atividades da empresa. Ou seja, os processos gerenciais garantem que os processos primários e os processos de suporte sejam bem executados e traçam planos para a continuidade das operações. Esses processos não agregam valor direto ao cliente, mas estão presentes antes, durante e depois do processo. Vejam que a questão apresenta conceitos associados aos processos gerenciais como se fosse de suporte. Logo, temos uma afirmação incorreta no enunciado.
Como o próprio nome já diz, os processos de suporte são aqueles que oferecem suporte aos processos primários, ou seja, são os processos que agregam valor ao produto ou ao negócio, mas que, por se tratarem de procedimentos internos, são visíveis aos clientes. Note que esses processos não entregam valor direto ao cliente, contudo são essenciais para a empresa e aumentam a capacidade de efetividade dos processos primários.
Os processos primários também são chamados de processos finalísticos. Eles são processos essenciais e que representam as atividades que uma organização desempenha para cumprir sua missão. Por isso, eles têm relação direta com o cliente, ou seja, são os processos mais perceptíveis ao consumidor.
- A análise de processos envolve a compreensão de processos de negócio, incluindo sua eficiência e eficácia para atendimento dos objetivos para os quais foram desenhados. O foco é compreender os processos atuais (“AS-IS”).
Já o desenho de processos é a concepção de novos processos de negócio e a especificação de como esses funcionarão, serão medidos, controlados e gerenciados. Envolve a criação do modelo futuro de processos de negócio (“TO-BE”) no contexto dos objetivos de negócio e de desempenho de processos, e fornece planos e diretrizes sobre como fluxos de trabalho, aplicações de negócio, plataformas tecnológicas, recursos de dados e controles financeiros e operacionais interagem com os processos.
Partindo destas definições, podemos marcar a afirmação acima como correta.
- De fato a notação usa piscinas e raias. Essa podem conter diversos símbolos. Os retângulos com cantos arredondados para representar tarefas, as setas que representam a sequência de fluxo e os losangos que apresentam os desvios. Um losango, em um ponto de ramificação, seleciona exatamente um caminho de saída dentre as alternativas existentes. Em um ponto de convergência, basta a execução completa de um braço de entrada para que seja ativado o fluxo de saída. Confesso que fiquei com uma pulga atrás da orelha com o retângulo representando um processo, mesmo assim acho que a afirmação está correta.
- 54. É difícil implementar BPM. Os principais problemas diante de qualquer mudança significativa são as barreiras humanas, inércia e interesses ocultos. Muitos trabalhadores do conhecimento resistem à transformação de processos, pois veem isso como uma diminuição de suas experiências e visão singular. Tal fato acaba por influenciar os custos de redefinição dos processos se eles forem efetivados. Mas, na minha percepção, os fatores descritos estão mais para um risco do que para um custo. Nesse contexto, a gestão de mudanças é fundamental para reduzir os riscos e custos, e maximizar os benefícios de grandes mudanças relacionadas ao negócio e à tecnologia que suporta as iniciativas BPM.
Quando falamos de custos, ele é o valor (normalmente monetário) associado ao processo. Pode assumir diferentes perspectivas, por exemplo, custo do recurso é a medida de valor associado aos recursos (humanos ou não) necessários para completar o processo e custo de oportunidade é o valor que é perdido no processo por não ter obtido seu resultado esperado. Logo, a alternativa está correta.
Gabarito: E C C C
-
Ano: 2018 Banca: CESPE Órgão: STM Cargo: Analista de Sistemas Questão: 71 a 74
Um sistema gerenciador de banco de dados (SGBD) instalado no Linux deve ser configurado de modo a permitir os seguintes requisitos:
I no máximo, 1000 conexões simultâneas;
II somente conexões originadas a partir do servidor de
aplicação com IP 10.10.10.2.
Tendo como referência essas informações, julgue os seguintes itens.
71 Caso o SGBD instalado seja o Postgres 9.6, para atendimento do requisito I, deve-se modificar o arquivo postgres.conf para o referido cluster; alterar o parâmetro max_connections para 1000; e reiniciar o serviço do SGBD.
72 Caso o SGBD instalado seja o Postgres 9.6, para atendimento do requisito II, deve-se modificar o arquivo pg_hba.conf para o referido cluster; alterar o parâmetro listen_addresses para o IP fornecido; e reiniciar o serviço do SGBD.
73 Caso o SGBD instalado seja o MySQL 5.7, para atendimento dos requisitos I e II, deve-se modificar o arquivo my.cnf, alterando-se os parâmetros max_user_connections para 1000 e connection_source para o IP fornecido; e reiniciar o serviço do SGBD.
74 Caso o SGBD instalado seja o Oracle 12C, os requisitos I e II podem ser atendidos em tempo de execução, respectivamente, por meio dos comandos SET system sessions = 1000 e SET system listener = 10.10.10.2.
Comentário: Vamos comentar cada uma das alternativas acima:
- O parâmetro max_connections determina o número máximo de conexões simultâneas para o servidor de banco de dados. O padrão geralmente é 100 conexões, mas pode ser menor se as configurações do kernel não o suportarem. Este parâmetro só pode ser configurado no início do servidor. Ou seja, para alterar esse valor precisamos reiniciar o SGBD. Contudo a afirmação apresenta o nome do arquivo de configuração incorreto, o certo seria postgresql.conf. Sendo assim, embora a alternativa tenha sido dada como correta, acho que cabe RECURSO!
- O arquivo pg_hba.conf indicará ao PostgreSQL como autenticar usuários que fazem acesso ao banco de dados. Em geral, as entradas do arquivo pg_hba.conf têm o seguinte layout:
# local DATABASE USER METHOD [OPTIONS]
# host DATABASE USER ADDRESS METHOD [OPTIONS]
# hostssl DATABASE USER ADDRESS METHOD [OPTIONS]
# hostnossl DATABASE USER ADDRESS METHOD [OPTIONS]
Vejamos alguns exemplo de regras que podem estar registradas em um arquivp pg_hba.conf:
# TYPE DATABASE USER ADDRESS METHOD
local all all trust
host all all 127.0.0.1/32 trust
host all all ::1/128 trust
O termo local diz que todos os usuários usando sockets Unix locais devem ser confiáveis para todos os bancos de dados. O método trust significa que nenhuma senha deve ser enviada para o servidor e as pessoas podem fazer login diretamente. As outras duas regras dizem que o mesmo se aplica às conexões do localhost 127.0.0.1 e ::1/128, que é um endereço IPv6.
Perceba que até agora não falamos do parâmetro listen_addresses. É porque ele não está no arquivo pg_hba.conf, ele é configurado no arquivo postgresql.conf. Desta forma, a alternativa está incorreta.
- Neste caso, não existe o connection_source no arquivo my.cnf. É possível restringir os IPs que acessam o banco usando a variável bind-address. Já a variável que limita a quantidade de requisições por usuários é max_user_connections. Se você quiser definir a quantidade de requisições globais use o termo max_connections. Logo, temos mais uma alternativa errada.
- Primeiramente para alterar o parâmetro que define a quantidade de sessões usamos o comando ALTER SYSTEM SET SESSIONS = 1000. Assim, essa alternativa já está errada. Ainda no servidor de banco de dados Oracle, o Oracle Net usa um processo ativo chamado listener para gerenciar conexões entre as aplicações e o servidor de Banco de Dados. As aplicações (remotas) não podem se conectar ao servidor de BD sem um listener. Um único listener pode servir múltiplas instâncias de BD e milhares de conexões clientes. Segue abaixo um exemplo de conteúdo do arquivo de configuração do listener, chamado listener.ora:
# listener.ora Network Configuration File:
LISTENER = (DESCRIPTION_LIST =
(DESCRIPTION =
(ADDRESS = (PROTOCOL = TCP)(HOST = localhost)(PORT = 1521)))
Gabarito: C(Recurso neles!) E E E
-
Ano: 2018 Banca: CESPE Órgão: STM Cargo: Analista de Sistemas Questão: 51 a 54
- CREATE TABLE IF NOT EXISTS ‘software’ (
- ‘id’ int NOT NULL,
- ‘nome’ varchar(70) NOT NULL,
- PRIMARY KEY (‘id’)
- ) DEFAULT CHARSET=utf8;
- INSERT INTO ‘software’ (‘id’, ‘nome’) VALUES
- (‘1’, ‘Programa ABC’),
- (‘2’, ‘Programa WYZ’),
- (‘3’, ‘Programa DFG’);
- CREATE TABLE IF NOT EXISTS ‘vsoftware’ (
- ‘idsoft’ int UNSIGNED NOT NULL REFERENCES software(id),
- ‘versao’ int(3) NOT NULL,
- ‘descricao’ varchar(70) NOT NULL,
- PRIMARY KEY (‘idsoft’,’versao’));
- INSERT INTO ‘vsoftware'(‘idsoft’, ‘versao’, ‘descricao’) VALUES
- (‘1’, ‘1’, ‘criacao do programa.’),
- (‘2’, ‘1’, ‘1a versao.’),
- (‘1’, ‘2’, ‘atualizacao na tela A.’),
- (‘1’, ‘3’, ‘adicao da tela C.’),
- (‘2’, ‘2’, ‘adicao da tela D.’);
Com base nos comandos MySQL 5.6 precedentes, julgue os itens a seguir.
75 Especialmente devido à expressão na linha 11, o comando a seguir, após executado, retornará três registros.
SELECT a.idsoft, a.versao, a.descricao
FROM ‘vsoftware’ a
INNER JOIN (
SELECT idsoft, MAX(versao) versao
FROM ‘vsoftware’
GROUP BY idsoft) b ON a.idsoft = b.idsoft
AND a.versao = b.versao;
76 A execução do comando
SELECT a.idsoft, a.versao, a.descricao
FROM ‘vsoftware’ a
LEFT OUTER JOIN ‘vsoftware’ b
ON a.idsoft = b.idsoft AND a.versao < b.versao
WHERE b.idsoft IS NULL;
retornará os seguintes dados.
idsoft versao descricao
1 3 adicao da tela C.
2 2 adicao da tela D.
77 A execução do comando
SELECT a.id
FROM ‘software’ a
where a.id not in (
SELECT b.idsoft
FROM ‘vsoftware’ b);
terá resultado idêntico à execução do comando a seguir.
SELECT distinct a.id
FROM ‘software’ a left outer join ‘vsoftware’ b
on a.id=b.idsoft;
78 A tabela vsoftware está na segunda forma normal (2FN), porque contém uma chave estrangeira referenciada à tabela software.
79 O comando ALTER TABLE software add data datetime; no MySQL 5.6 adiciona um novo campo data à tabela software.
80 O comando a seguir no MySQL 5.6 modifica o tipo do campo nome para CHAR na tabela software.
ALTER TABLE software MODIFY nome char(100);
Comentário: Vamos comentar cada uma das questões acima:
- Essa alternativa tem uma consulta interna que agrupa por software id. Veja que cada software vai retornar sua última versão na outra coluna. Como temos dois softwares o resultado intermediário são apenas duas tuplas. Logo em seguida, temos um inner join que vai compara o valor da versão e do id na clausula ON. Tal fato, mantem apenas duas tuplas no resultado. Logo, a alternativa está errada.
- A lógica para resolver essa questão é seguinte, não existirá elementos no lado direito quando a retrição “a.versao < b.versao” não for satisfeita. Logo, temos as seguintes tuplas abaixo onde b.idsoft IS NULL, isso é de fato o que consta na sugestão de resposta. Logo, a afirmação está correta.
(‘1’, ‘3’, ‘adicao da tela C.’),
(‘2’, ‘2’, ‘adicao da tela D.’);
- A primeira retornará os programas que não tem versões ainda publicadas, neste caso concreto, apenas o id 3. Já a segunda, retornará todos os valores de id que tenham ou não versão publicada. Como elas não apresentam o mesmo resultado, temos uma alternativa incorreta.
- A tabelas está de fato na segunda forma normal, mas isso acontece pois não existe dependência parcial da chave primária. A justificativa presente na alternativa afirma algo diferente disto, logo temos uma alternativa errada.
- A afirmação usa a sintaxe correta do MySQL para alteração de tabela. Lembrando que o column é opcional. Logo, alternativa correta.
- Para mudar o tipo de dados ou a definição da coluna você pode usar o comando MODIFY que é uma extensão do MySQL para ser compatível com o SGBD Oracle. É uma forma de mudar a definição sem mexer no nome do atributo. Desta forma, a alternativa está correta.
Gabarito: E C E E C
-
Ano: 2018 Banca: CESPE Órgão: STM Cargo: Analista de Sistemas Questões: 81 e 82
Julgue os itens subsequentes, a respeito do Postgres 9.6.
81 Ao se criar uma trigger, a variável especial TG_OP permite identificar que operação está sendo executada, por exemplo, DELETE, UPDATE, INSERT ou TRUNCATE.
82 Nas instruções seguintes, a palavra-chave IMMUTABLE indica que a função criada não pode modificar o banco de dados. CREATE FUNCTION add(integer, integer) RETURNS integer
AS ‘select $1 + $2;’
LANGUAGE SQL
IMMUTABLE
RETURNS NULL ON NULL INPUT;
Comentário: Vamos comentar as alternativas acimas. Primeiramente a questão 81 está correta. De fato, TG_OP é uma variável do tipo texto que pode ser preenchida com os valores INSERT, UPDATE, DELETE ou TRUNCATE que identificam quais operações irão disparar o TRIGGER. Vejamos alguns exemplos:
CREATE TRIGGER emp_stamp BEFORE INSERT OR UPDATE ON emp
FOR EACH ROW EXECUTE PROCEDURE emp_stamp();
CREATE TRIGGER emp_audit
AFTER INSERT OR UPDATE OR DELETE ON emp
FOR EACH ROW EXECUTE PROCEDURE process_emp_audit();
- A questão 82 trata dos parâmetros IMMUTABLE, STABLE, VOLATILE. Esses atributos informam ao otimizador de consulta sobre o comportamento da função. No máximo, uma opção pode ser especificada. Se nenhum deles aparecer, VOLATILE é a definido por padrão.
Ser o valore passado for IMMUTABLE vai indicar que a função não pode modificar o banco de dados e sempre retorna o mesmo resultado quando dados os mesmos valores de argumento; ou seja, não faz pesquisas de banco de dados ou, de outra forma, usa informações que não estão diretamente presentes na lista de argumentos. Se esta opção for dada, qualquer chamada da função com argumentos constantes pode ser imediatamente substituída pelo valor da função. Desta forma, temos mais uma alternativa correta.
STABLE indica que a função não pode modificar o banco de dados, e que, dentro de uma única tabela, retornará consistentemente o mesmo resultado para os mesmos valores de argumento, mas que seu resultado pode mudar em declarações SQL. Esta é a seleção apropriada para funções cujos resultados dependem de pesquisas de banco de dados, variáveis de parâmetros (como o fuso horário atual), etc.
VOLATILE indica que o valor da função pode mudar mesmo dentro de uma varredura de tabela única, portanto, nenhuma otimização pode ser feita. Relativamente poucas funções de banco de dados são voláteis nesse sentido; alguns exemplos são aleatórios (), currval (), timeofday (). Mas note que qualquer função que tenha efeitos colaterais deve ser classificada como volátil, mesmo que seu resultado seja bastante previsível, para evitar que as chamadas sejam otimizadas; um exemplo é setval ().
Gabarito: C C
-
Ano: 2018 Banca: CESPE Órgão: STM Cargo: Analista de Sistemas Questões: 83 a 85
Acerca do Oracle 12C, julgue os próximos itens.
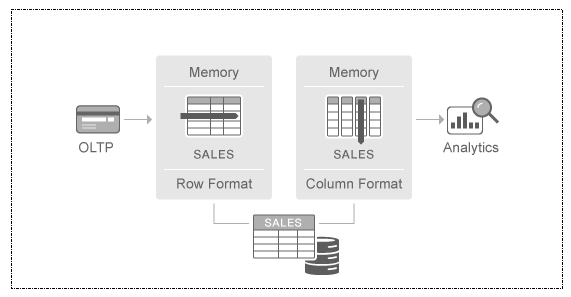
83 Especialmente voltado para o armazenamento de dados de sistemas de suporte a decisão (DSS) e data warehouse, os dados no Oracle podem ser armazenados em uma nova área opcional denominada In-Memory (IM). A IM é um suplemento que substitui a system global area (SGA), pois se sobrepõe ao cache de buffer do banco de dados, permitindo alto poder de processamento ao varrer dados colunares rapidamente por meio de vetorização.
84 Os dados nos SGBDs são organizados em blocos, em que os sistemas de suporte à decisão (DSS) e os ambientes de banco de dados de data warehouse tendem a se beneficiar de valores de tamanho de bloco maiores.
85 Os blocos de dados são organizados em cabeçalho (row header) e dados (column data); a cada nova transação, o registro é armazenado como uma nova linha na tabela e, assim, um registro é armazenado em várias colunas em blocos de dados no disco.
Comentário: Vamos comentar cada uma das alternativas:
- Vamos começar relembrando alguns conceitos. Uma Instância Oracle contém memória e conjunto de processos em background. A memória é dividida em duas áreas distintas: System Global Area (SGA) e Program Global Area (PGA). O Oracle cria processos servidores para lidar com os pedidos de processamento dos usuários conectados à instancia. Uma das mais importantes tarefas do Processo Servidor: ler blocos de dados de objetos a partir de datafile dentro de um buffer do banco de dados que por padrão, armazena os dados no buffer cache do banco de dados Oracle em formato de linha.
A partir do 12c o Oracle Database Release 1 (12.1.0.2) adicionou uma nova área opcional na SGA chamado de In-Memory, que são objetos armazenados com o novo formato In-Memory Column Store (IM column store). A IM Column store é opcional e armazena cópias das tabelas, partitions, colunas, materialized views (objetos especificados como INMEMORY usando DDL) em um formato especial de colunas otimizadas para leituras rápidas.
A IM column store é um suplemento em vez de ser um substituto para o cache de buffer do banco de dados. A IM column store não substitui o buffer cache. Mas ambas as áreas de memória podem armazenar os mesmos dados em formatos diferentes e não é necessário para objetos armazenados na IM column store serem carregados no buffer cache do banco de dados, ou seja, os objetos são armazenados unicamente na IM column store. Sendo assim, temos uma afirmação incorreta.
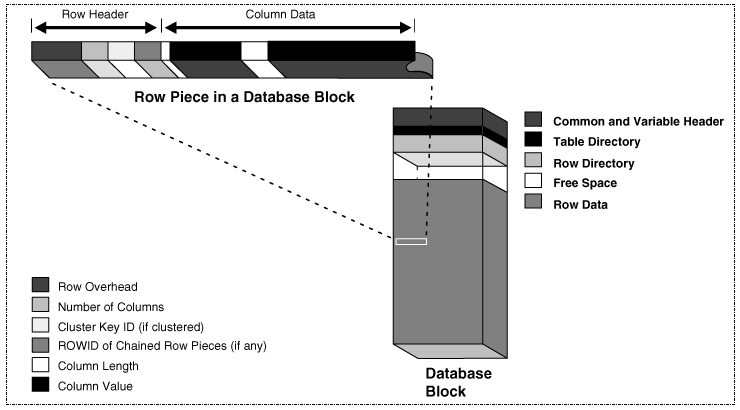
- Um bloco é um conjunto contíguo de bits ou bytes que forma uma unidade de dados identificável. Em alguns bancos de dados, um bloco é a menor quantidade de dados que um programa pode solicitar. É um múltiplo de um bloco do sistema operacional, que é a menor quantidade de dados que podem ser recuperados do armazenamento ou da memória. Vários blocos em um banco de dados compreendem uma extensão.
No Oracle, o valor do DB_BLOCK_SIZE em vigor quando você cria o banco de dados determina o tamanho dos blocos. O valor deve permanecer definido como seu valor inicial. Para Real Application Clusters, este parâmetro afeta o valor máximo do parâmetro de armazenamento FREELISTS para tabelas e índices. O Oracle usa um bloco de banco de dados para cada grupo freelist. O sistema de suporte à decisão (DSS) e os ambientes de banco de dados de data warehouse tendem a se beneficiar de valores de tamanho de bloco maiores.
- A figura abaixo descreve um bloco de arquivos no Oracle. Veja que existe um cabeçalho de bloco, que contém o endereço do bloco de dados, o diretório da tabela e o diretório da linha e os slots de transação usados quando as transações fazem alterações em linhas do bloco. Esses cabeçalhos crescem de cima para baixo. Temos também os espaços de dados, esses dados de colunas são inseridos no bloco de baixo para cima. Veja que quando inserirmos os dados eles serão armazenados os registros em tabelas organizadas em linhas por colunas e estruturadas em blocos.
Gabarito: E C C
-
Ano: 2018 Banca: CESPE Órgão: STM Cargo: Analista de Sistemas Questões: 86 a 90
Julgue os itens que se seguem, a respeito do processamento de transações e otimização de desempenho do SGBD e de consultas SQL.
86 O controle de nível de isolamento de transações é importante para gerenciar a forma como as transações concorrentes se comportarão no SGBD. No Postgres 9.6, o nível de isolamento padrão é READ COMMITTED, mas pode ser alterado para SERIAZABLE por meio do comando SET TRANSACTION ISOLATION LEVEL SERIAZABLE.
87 No MySQL 5.6, o modo padrão de execução das transações é autocommit, o qual faz que as mudanças realizadas se tornem permanentes após a execução bem-sucedida desse comando; entretanto, esse modo será desabilitado implicitamente, se uma série de instruções for iniciada por meio do comando START TRANSACTION.
88 No Oracle 12C, a Automatic Workload Repository (AWR) é uma funcionalidade similar ao autovacuum no Postgres 9.6, haja vista que ambos processam e mantêm estatísticas de desempenho para detecção de problemas e manutenção automática do banco de dados, por exemplo, reusando, ajustando e excluindo dados temporários e reusando espaço em blocos por linhas excluídas.
89 No MySQL 5.6, o banco de dados information_schema guarda dados estatísticos e eventos para serem utilizados caso se queira encontrar problemas de velocidade de acesso aos dados e(ou) problemas de integridades no SGBD.
90 No MySQL 5.6, os índices são usados para, entre outras operações, desconsiderar linhas a serem pesquisadas e(ou) encontrar linhas abrangidas pelo WHERE mais rapidamente
Comentário: Vamos comentar cada uma das alternativas acima:
- Por padrão, o PostgreSQL é executado no modo de isolamento de transação READ COMMITTED. Isso significa que cada declaração dentro de uma transação obterá um novo instantâneo dos dados, que será constante ao longo da consulta. Para mudar de nível de isolamento usamos o comando SET TRANSACTION que possui a seguinte sintaxe.
SET TRANSACTION transaction_mode [, …]
SET TRANSACTION SNAPSHOT snapshot_id
SET SESSION CHARACTERISTICS AS TRANSACTION transaction_mode [, …]
onde transaction_mode pode ser definido da seguinte forma:
ISOLATION LEVEL { SERIALIZABLE | REPEATABLE READ | READ COMMITTED | READ UNCOMMITTED }
READ WRITE | READ ONLY
[ NOT ] DEFERRABLE
Logo a afirmação estaria correta. Contudo, observem que o enunciado apresenta o termo SERIAZABLE, quando o correto seria SERIALIZABLE. Sendo assim: RECURSO NELES!!!
- Por padrão, o MySQL é executado no modo autocommit, o que significa que as alterações feitas por declarações ou comandos individuais são commitados no banco de dados imediatamente para torná-los permanentes. Com efeito, cada declaração ou comando é uma transação implicitamente. Para executar as transações explicitamente, desative o modo de autocommit e depois diga ao MySQL quando confirmar ou reverter as mudanças.
Uma forma de executar uma transação é emitir uma declaração de START TRANSACTION (ou BEGIN) para suspender o modo de autocommit, executar as declarações que compõem a transação e encerrar a transação com uma declaração de COMMIT para tornar as alterações permanentes. Se ocorrer um erro durante a transação, você pode cancelar emitindo uma instrução ROLLBACK para desfazer as alterações. Logo, a alternativa está correta.
- Falamos sobre AWR e Autovacuum na nossa revisão para o concurso do STM. O PostgreSQL e outros bancos de dados relacionais usam uma técnica chamada Multi-Version Concurrency Control (MVCC) para manter o controle das transações. Uma penalidade de espaço surge quando usamos o MVCC, ela é conhecida como inchaço. O PostgreSQL precisa de ajuda de uma ferramenta externa chamada VACUUM para poder limpar essa “sujeira”.
As tabelas e índices inchados não somente desperdiçam espaço, como também deixam as consultas mais lentas. Então, isso não é só uma questão de conseguir mais espaço no disco rígido. Antigamente, os DBAs precisavam executar o VACUUM manualmente. Hoje, é possível configurar um deamon chamado Autovacuum para executar essas limpezas em momentos oportunos.
Veja que Autovacuum não guarda nenhuma relação de similaridade funcional com o AWR. Podemos afirmar, portanto, que a alternativa está incorreta. Sabemos que o AWR significa Automatic Workload Repository, ou seja, é um repositório de informações a respeito da carga de trabalho do banco de dados. O framework do AWR coleta, processa e mantém estatísticas de desempenho para possibilitar detecção de problemas e é a base para as tarefas de tuning automáticas do Oracle. Estas estatísticas são coletadas através de snapshots regulares e armazenadas no AWR por um período definido, elas são baseadas no momento do snapshot e podem ser utilizadas para elaborar um relatório. Os valores capturados pelo snapshot representam as mudanças em cada estatística coletada no período.
- No MySQL, o INFORMATION_SCHEMA fornece acesso a metadados de banco de dados, informações sobre o servidor MySQL, como o nome de um banco de dados ou tabela, o tipo de dados de uma coluna ou privilégios de acesso. Outros termos que às vezes são usados para esta informação são o dicionário de dados e o catálogo do sistema.
O INFORMATION_SCHEMA é um banco de dados dentro de cada instância do MySQL, trata-se do local que armazena informações sobre todos os outros bancos de dados que o servidor MySQL mantém. O banco de dados INFORMATION_SCHEMA contém várias tabelas somente leitura. Eles são, na verdade, visualizações, não tabelas de base, portanto, não há arquivos associados a elas, e você não pode definir gatilhos ou triggers. Além disso, não há um diretório de banco de dados com esse nome, as tabelas são construídas temporariamente enquanto a instância do SGBD estiver executando.
Existe outro esquema padrão no MySQL denominado PERFORMANCE_SCHEMA que é usado para inspecionar a execução de consultas e eventos em tempo real. Esse esquema destina-se a fornecer acesso a informações úteis sobre a execução do servidor, tendo um impacto mínimo no desempenho. O PERFORMANCE_SCHEMA centra-se principalmente nos dados de desempenho. Isso difere de INFORMATION_SCHEMA, que serve para inspeção dos metadados. Sendo assim, a afirmação mistura os dois conceitos, logo está incorreta.
- O MySQL usa índices de várias maneiras:
- Os índices são usados para acelerar pesquisas de linhas que combinam termos de uma cláusula WHERE ou linhas que combinam tuplas de outras tabelas quando executam junções. Por isso, a alternativa está correta.
- Para consultas que usam as funções MIN() ou MAX(), o MySQL pode encontrar o menor ou maior valor em uma coluna indexada rapidamente sem examinar cada linha.
- O MySQL geralmente pode usar índices para executar eficientemente operações de classificação e agrupamento para cláusulas ORDER BY e GROUP BY.
Gabarito: C (Recurso Neles!) C E E C
Qualquer dúvida estou às ordens,
Forte abraço e bons estudos,
Thiago Cavalanti