Marcos Medeiros da Silva
Aprovado em 13° lugar no concurso PF para o cargo de Agente de Polícia Federal
Aprovado na PF: Marcos Silva
Abaixo comentamos as questões de banco de dados da prova do Alerj deste último final de semana. São 10 questões de banco de dados e BI dos mais variados assuntos, vamos aos comentários.

Observe o seguinte relatório OLAP.
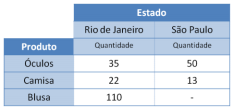
A alternativa que ilustra o resultado da operação Dice é
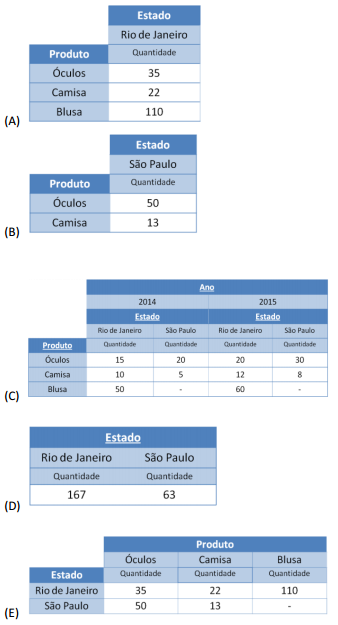 Comentário: Comentamos na nossa aula de revisão para alerj que o DICE corta o cubo de dados em mais de uma dimensão. Ou, em outras palavras, restringe o escopo de análise em duas dimensões distintas. Tal fato pode ser observado na alternativa B, nela da dimensão localização é reduzida apenas ao escopo do estado de São Paulo e a dimensão produto é restrita apenas a óculos e camisa.
Comentário: Comentamos na nossa aula de revisão para alerj que o DICE corta o cubo de dados em mais de uma dimensão. Ou, em outras palavras, restringe o escopo de análise em duas dimensões distintas. Tal fato pode ser observado na alternativa B, nela da dimensão localização é reduzida apenas ao escopo do estado de São Paulo e a dimensão produto é restrita apenas a óculos e camisa.
Gabarito: B.
Daniel está desenvolvendo um Data Warehouse para analisar os dados do Censo Escolar. A fonte de dados está em um arquivo CSV e descrita em um documento, conforme parcialmente ilustrado nas figuras a seguir.
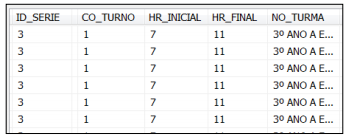
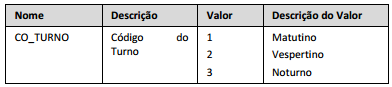
Para carregar esses dados no Data Warehouse com a descrição dos turnos no lugar de seu código, Daniel deve desenvolver um programa para ler os dados do arquivo, realizar transformações e carregar o resultado no banco de dados.
A ferramenta a ser utilizada por Daniel é:
(A) ETL;
(B) OLAP;
(C) Data Mining;
(D) ODBC;
(E) XSLT.
Comentário: A definição presente no enunciado claramente nos aponta para a ferramenta responsável pela extração, transformação e carga dos dados. Essa carga pode ser feita a partir de um banco de dados relacional, um arquivo de texto plano ou algum outro documento semiestruturado, por exemplo.
Gabarito: A.
Observe o seguinte Modelo Multidimensional de Dados.
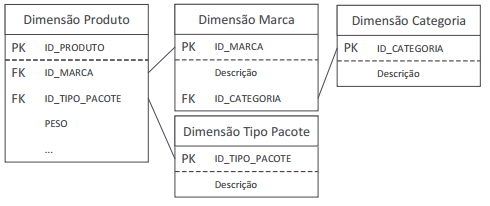
A técnica de modelagem multidimensional utilizada para normalizar a dimensão, movendo os campos de baixa cardinalidade para tabelas separadas e ligadas à tabela original através de chaves artificiais, é:
(A) Slowly Changing Dimension;
(B) Conformed Dimension;
(C) Degenerated Dimension;
(D) Snowflaked Dimension;
(E) Role-Playing Dimension.
Comentário: A questão apresente o conceito de modelo de dados floco de neve de forma um pouco mais elaborada. Contudo, você pode perceber que a característica determinante para esse tipo de modelagem multidimensional que é ter dimensões normalizadas está presente, tanto na figura quanto na descrição.
Gabarito: D.
O SGBD Oracle 11g armazena logicamente seus dados em tablespaces e fisicamente em datafiles associados à tablespace. Considere um banco de dados com a tablespace tbs_03.
Para aumentar esse banco, adicionando o datafile tbs_f04.dbf à tablespace tbs_03, deve-se executar o comando:
(A) CREATE TABLESPACE tbs_03 DATAFILE 'tbs_f04.dbf';
(B) ALTER TABLESPACE tbs_03 ADD DATAFILE 'tbs_f04.dbf' SIZE 100K;
(C) CREATE DATAFILE 'tbs_f04.dbf' ON tbs_03 TABLESPACE;
(D) ALTER DATABASE AUTOEXTEND 'tbs_f04.dbf' ON tbs_03;
(E) ADD DATAFILE 'tbs_f04.dbf' ON TABLESPACE tbs_03 SIZE 100K;
Comentário: O comando do Oracle responsável pela alteração de espaços de tabela pode ser usado para diferentes propósitos. Pela sintaxe do comando podemos observar esse fato:

Nosso interesse para responder à questão está na adição de um novo DATAFILE ao TABLESPACE. Na definição do file_specification acima temos a possibilidade de definir o tamanho (SIZE) para o DATAFILE. Veja na figura abaixo.

Desta forma, podemos considerar a alternativa B como correta por apresentar uma sintaxe consistente com o comando em questão.
Gabarito: B.
Observe a figura a seguir, que representa um Modelo de Entidades e Relacionamentos utilizando a notação IDEF1X (Integrated DEFinition for Information Modelling).
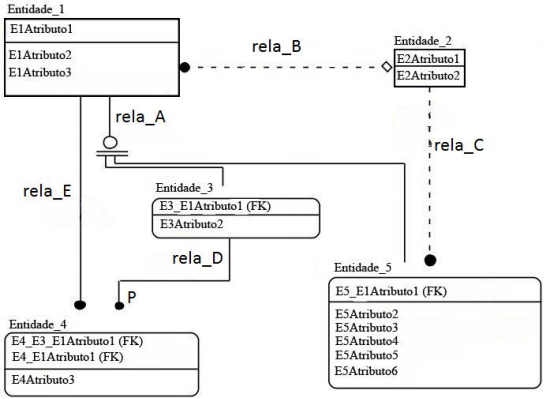
Com base na sintaxe da notação utilizada no modelo, é correto afirmar que:
(A) "Entidade_1" é uma entidade dependente;
(B) "rela_A" indica que o conjunto de entidades que representam um subtipo ou subclassificação da "Entidade_1" está incompleto;
(C) "rela_C" é um relacionamento onde cada instância da entidade filho está relacionada a zero ou a uma instância da entidade pai;
(D) "rela_D" indica que "Entidade_3" se relaciona com uma ou mais "Entidade_4";
(E) "rela_B" é um relacionamento onde cada instância da entidade filho está relacionada a uma ou mais instâncias da entidade pai.
Comentário: Essa questão merece o comentário de cada uma das alternativas.
Na letra A temos a afirmação que a entidade_1 é dependente. Lembre-se que o que caracteriza a dependência no modelo em questão é o fato das pontas do retângulo serem arredondas. Sendo assim, as entidades 3, 4 e 5 são dependentes.
Já na alternativa B temos a notação representa uma herança completa (dois traços abaixo do círculo) e exclusiva (apenas um círculo). Sendo assim não podemos dizer que a Entidade_1 está incompleto.
A relação “rela_C” representa um relacionamento 1:N opcional. Sendo assim, a alternativa C também se encontra incorreta.
A letra D apresenta um relacionamento apresenta um relacionamento obrigatório 1:N. Está é a nossa resposta!
O erro da alternativa E está em dizer que cada instância da entidade filho está relacionado a uma ou mais instâncias da entidade pai. Quando na realidade a ideia é justamente o contrário. Pense que um Pai pode ter vários filhos, mais um filho só deve ter apenas um pai.
Gabarito: D.
Quando uma instância é iniciada, o SGBD Oracle 11g aloca uma área de memória e inicia processos de background. A memória alocada para variáveis de sessão, como informações de logon e outras informações necessárias por uma sessão do banco de dados, é a:
(A) Reserved Pool;
(B) Data Dictionary Cache;
(C) User Global Area;
(D) Java Pool;
(E) Database Buffer Cache
Comentário: A Área Global do Usuário (UGA) é a memória associada a uma sessão de usuário. Nesta sessão, onde a memória é alocada para as variáveis de sessão, como informações de logon e outras informações exigidas por uma sessão de banco de dados. Essencialmente, o UGA armazena o estado da sessão. A figura descreve o UGA pode ser vista abaixo:
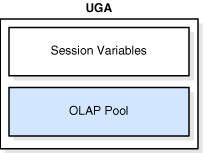
Vejam que o comentário assim está diretamente associado ao texto do enunciado. Sendo assim, podemos concluir que nossa resposta está na alternativa C.
Gabarito: C
Observe as figuras a seguir que ilustram, parcialmente, dois procedimentos escritos em PL/SQL e implementados em uma instância de banco de dados Oracle 11g. Considere que a execução de proced1 foi submetida diretamente no prompt do Oracle SQL *Plus®.
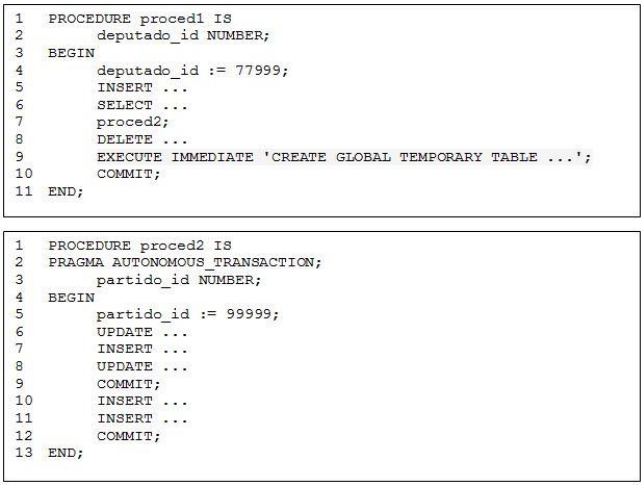
A transação iniciada na linha 5 de proced1 terá seus efeitos gravados permanentemente no banco de dados quando:
(A) a rotina proced2 iniciar;
(B) o COMMIT da linha 9 de proced2 for executado;
(C) o EXECUTE IMMEDIATE da linha 9 de proced1 for executado;
(D) o COMMIT da linha 10 de proced1 for executado;
(E) o usuário desconectar voluntariamente do Oracle 11g durante a execução da linha 10 de proced2.
Comentário: [ATUALIZAÇÃO] De acordo com a documentação do guia do usuário de PL/SQL da Oracle, o comando EXECUTE IMMEDIATE prepara e executa imediatamente uma instrução SQL ou um bloco anônimo PL/SQL. Ele permite que instruções DDL ou DCL possam ser executadas dentro de um bloco PL/SQL. Os dados gravados efetivamente são apenas os que são manipulados pelo comando, não considerando as demais instruções executadas dentro da procedure.
Contudo existe um ponto importante que foi justamente a nuance que o examinador quis questionar na prova. Vejam o que diz a documentação oficial da oracle sobre commits em transações: "A user runs a DDL statement such as CREATE, DROP, RENAME, or ALTER. If the current transaction contains any DML statements, Oracle first commits the transaction, and then runs and commits the DDL statement as a new, single statement transaction."
Observem que o comando EXECUTE IMMEDIATE está criando uma tabela global temporária. Neste caso temos um comando DDL. Sendo assim, todos os demais comandos DML da transação serão Commitados nesta linha da transação.
Gabarito: C
Em banco de dados, a finalidade do processo de normalização é evitar redundâncias e, portanto, evitar certas anomalias de atualização de dados. Considere as dependências funcionais entre os atributos das seguintes entidades:
PACIENTE(ID_PACIENTE determina NOME_PACIENTE);
MEDICO(ID_MEDICO determina CRM_MEDICO, NOME_MEDICO);
CONSULTA(ID_PACIENTE, ID_MEDICO determinam DATA_ATEND, HORA_ATEND);
Sabendo-se que o atributo sublinhado é a chave primária, a alternativa que apresenta as entidades e seus atributos na Terceira Forma Normal (3FN) é:
(A) PACIENTE (ID_PACIENTE, NOME_PACIENTE, ID_MEDICO, DATA_ATEND, HORA_ATEND)
MEDICO (ID_MEDICO, CRM_MEDICO, NOME_MEDICO)
CONSULTA (CRM_MEDICO, DATA_ATEND, HORA_ATEND)
(B) PACIENTE (ID_PACIENTE, NOME_PACIENTE)
MEDICO (ID_MEDICO, CRM_MEDICO, NOME_MEDICO)
CONSULTA (ID_PACIENTE, NOME_MEDICO, DATA_ATEND, HORA_ATEND)
(C) PACIENTE (ID_PACIENTE, NOME_PACIENTE, ID_MEDICO)
MEDICO (ID_MEDICO, CRM_MEDICO, NOME_MEDICO)
CONSULTA (ID_PACIENTE, DATA_ATEND, HORA_ATEND)
(D) PACIENTE (ID_PACIENTE, NOME_PACIENTE)
MEDICO (ID_MEDICO, CRM_MEDICO, NOME_MEDICO)
CONSULTA (ID_PACIENTE, ID_MEDICO, DATA_ATEND, HORA_ATEND)
(E) PACIENTE (ID_PACIENTE, NOME_PACIENTE)
MEDICO (ID_MEDICO, CRM_MEDICO, NOME_MEDICO)
CONSULTA (ID_PACIENTE, CRM_MEDICO, NOME_MEDICO,
DATA_ATEND, HORA_ATEND)
Comentário: Para chegarmos até a terceira forma normal temos que cumprir alguns requisitos. As relações do modelo não podem ter atributos compostos ou multivalorasdos (1FN), não pode existir em cada uma das relações dependência parcial (2FN) nem dependência transitiva (3FN). Ao ajustar o modelo podemos encontra nossa resposta na alternativa D.
Gabarito: D
Observe a instrução SQL a seguir, que representa uma consulta à tabela "TB_Produto" de uma instância de banco de dados Oracle 11g.
SELECT desc_prod
FROM TB_Produto
WHERE to_char(data_saida,'YYYY-MM-DD') = '2016-01-04';
A consulta lista a descrição dos produtos que tiveram data de saída do estoque em 04 de Janeiro de 2016. A coluna que armazena a data de saída do produto não é chave primária. Visando melhorar o desempenho das consultas à coluna “data_saida”, o Administrador de Banco de Dados deve criar um índice do tipo:
(A) B-Tree;
(B) Function-Based;
(C) Bitmap;
(D) Hash;
(E) Unique.
Comentário: Um dos maiores problemas com índices é que os índices são muitas vezes suprimidos por desenvolvedores e usuários ad-hoc. Desenvolvedores que usam funções muitas vezes suprimem os índices criados pelo banco de dados. No Oracle, existe uma maneira de combater este problema.
Os índices baseados em função permitem criar um índice baseado em uma função ou expressão. O valor da função ou expressão é especificado pela pessoa que cria o índice e é armazenado no índice. Os índices baseados em funções podem envolver várias colunas, expressões aritméticas ou ainda uma função PL/SQL ou uma chamada em C. O exemplo a seguir mostra como criar um índice baseado em função:
![]()
Desta forma, podemos marcar nosso gabarito na alternativa B. Para quem tiver curiosidade o mestre Fábio Prado fez uma palestra sobre esse assunto, os slides também estão disponíveis aqui.
Gabarito: B
No SQL Server 2012, os seguintes comandos foram executados individualmente para criar as tabelas no banco de dados MeuBanco.

A figura abaixo representa o conteúdo das tabelas Tab1, Tab2 e Tab3 de MeuBanco.
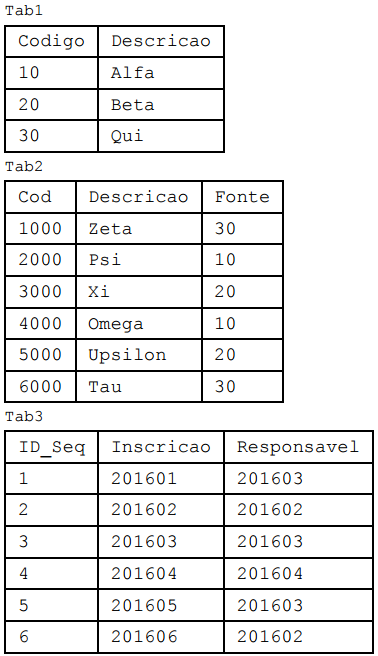
Em momento posterior, os comandos abaixo foram executados individualmente na seguinte ordem:
TRUNCATE TABLE Tab1;
DELETE TOP (2) FROM Tab2 WHERE Cod < 4000;
TRUNCATE TABLE Tab3;
Considere a execução de commit implícitos e desconsidere quaisquer comandos reconhecidos unicamente por aplicativos clientes para acesso aos bancos de dados do SQL Server 2012. Após a execução dos comandos, é correto afirmar que:
(A) as linhas de Tab1 foram removidas e foi registrada uma entrada no log de transações para cada linha excluída;
(B) as linhas, a estrutura da tabela, as colunas e as constraints de Tab1 forma removidas;
(C) Tab2 ficou vazia, mas sua estrutura não sofreu alterações;
(D) os dados de Tab3 foram removidos e suas respectivas páginas de dados foram desalocadas;
(E) Tab3 teve seus dados removidos e foi registrada uma entrada no log de transações para cada linha excluída.
Comentário: O comando TRUNCATE vai remover todas as linhas da tabela e suas respectivas páginas sem gravar essa modificação nos arquivos de log. A estrutura da tabela permanece disponível no SGBD, agora sem dados armazenados. Sendo assim podemos marcar nossa resposta na alternativa D.
Gabarito: D
Espero que aproveitem os comentários acima para fazer uma revisão sobre o assunto. A FGV é uma das bancas que cobra banco de dados em um nível mais elevado.
Qualquer dúvida estou às ordens,
Thiago