Juliane Dionisio
Aprovada em 1° lugar no concurso TRT-10 para o cargo de Analista Judiciário - Especialidade: Arquivologia
Aprovada em 1° lugar no concurso TRT-10: Juliane Dionisio
Olá, pessoal. Tudo certo? No artigo de hoje (Modelo Conceitual e Lógico para SEFAZ-SP) trataremos sobre dois importantes assuntos:
Para contextualizar, o projeto de banco de dados é uma etapa crucial no desenvolvimento de sistemas de informação, onde a estrutura e organização dos dados são cuidadosamente planejadas para atender aos requisitos do sistema e garantir eficiência no armazenamento e recuperação das informações.
Este processo é geralmente dividido em três modelos distintos: o modelo conceitual, o modelo lógico e o modelo físico.
Em suma, os modelos conceitual, lógico e físico trabalham em conjunto para transformar os requisitos do sistema em uma estrutura de banco de dados funcional e otimizada.
Este artigo explorará o modelo conceitual e lógico com foco naquilo que está sendo cobrado em concurso público.
Sem mais delongas, vamos lá.
Iniciando o artigo sobre Modelo Conceitual e Lógico para SEFAZ-SP, vejamos inicialmente sobre o modelo conceitual.
O modelo conceitual estabelece uma visão abstrata do banco de dados, identificando as entidades principais e os relacionamentos entre elas. Ele fornece uma compreensão de alto nível do domínio do problema e serve como base para os modelos subsequentes.
Perfeito, agora vejamos sobre o Modelo Entidade-Relacionamento no contexto do Modelo Conceitual.
Modelo Entidade-Relacionamento (MER): descreve um contexto (“mini-mundo”) em termos de entidades, relacionamentos e atributos.
Tipos de Entidade:
Forte (independente): existência independe de outras entidades
Fraca: a existência depende de outra entidade (Condição 1) e não pode ser identificada unicamente apenas por seus atributos (Condição 2)
Associativa: a associação de uma entidade a um relacionamento
Classificação de Relacionamentos
Quanto ao Grau: número de tipos de entidades que participam de um relacionamento – ex. binário
Quanto à Cardinalidade: Representa a quantidade de ocorrências ou instâncias de cada entidade presente no relacionamento – ex. 1:1, 1:N.
Restrição:
Participação Total: toda instância de uma Entidade A deve possuir uma ou mais instâncias de uma Entidade B associada a ela. – ex. 1:1 ou 1:N
Participação Parcial: nem toda instância de uma Entidade A deve possuir uma instância de uma Entidade B associada a ela. – ex. 0:1 ou 0:N
Outras informações:
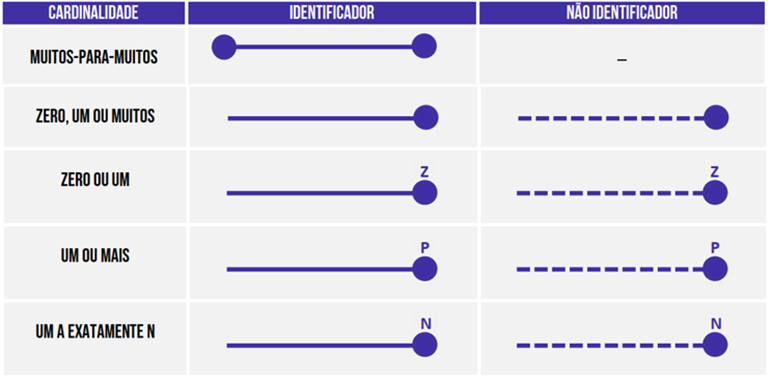
Cardinalidade mínima (restrição de participação): 0 (cardinalidade mínima opcional -ex. 0:N) ou 1 (cardinalidade mínima obrigatória – ex. 1:N)
Cardinalidade máxima (razão da cardinalidade): 1 ou N
Classificação dos Atributos
Quanto ao valor: monovalorado ou multivalorado
Quanto ao Identificador: com identificador (círculo preto, sublinhado ou asterisco) ou sem identificador → um identificador representa uma ocorrência de forma única – ex. CPF.
Além disso, é válido conhecer a notação DER.
Notação do Diagrama Entidade-Relacionamento (DER)
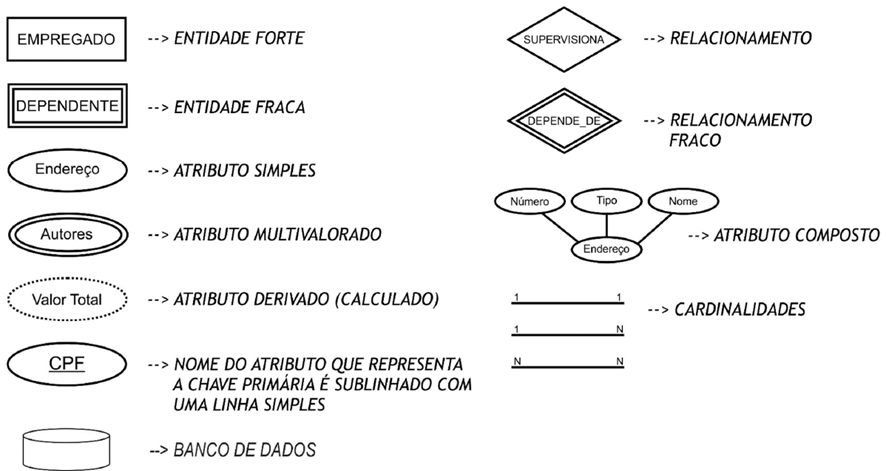
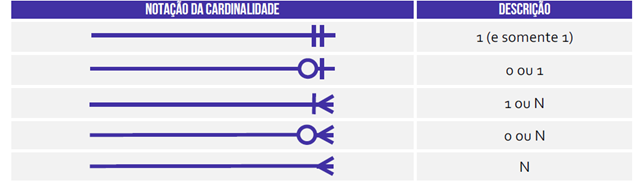
Continuando no artigo sobre Modelo Conceitual e Lógico para SEFAZ-SP, é válido conhecer a Notação Pé-de-Galinha (Crow’s Foot), que vez ou outra é cobrada em prova.
A entidade é representada da seguinte forma.

Enquanto a cardinalidade temos que:
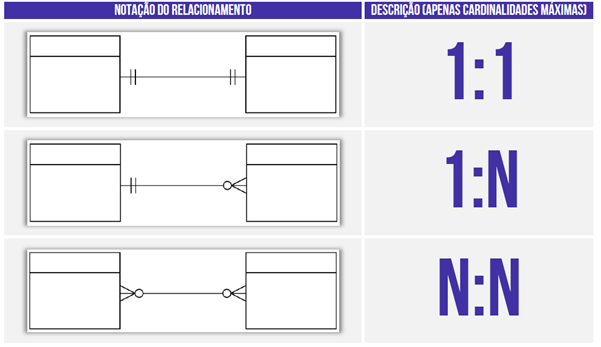
Além disso, temos as seguintes notações de relacionamento.
Prosseguindo no artigo sobre Modelo Conceitual e Lógico para SEFAZ-SP, vamos entender um pouco melhor sobre modelo lógico.
O modelo lógico traduz o modelo conceitual em estruturas de dados específicas para o sistema de gerenciamento de banco de dados (SGBD) que será utilizado. Aqui, as entidades são mapeadas para tabelas, e os relacionamentos são definidos por chaves primárias e estrangeiras. Restrições de integridade e outras regras de negócio também são especificadas neste nível.
Também é válido saber que existem outras implementações além do Modelo Relacional, como Modelo em rede, hierárquico, entre outros.
Agora vamos tratar sobre o Modelo Relacional.
Modelo Relacional: é capaz de representar dados por meio de uma linguagem matemática, utilizando teoria de conjuntos e lógica de predicado de primeira ordem
É muito importante se familiarizar com as nomenclaturas.
Tabela (Relação): representa os dados e os relacionamentos entre dados
Linha (Tupla/Instância/Registro): valores de dados
Coluna (atributo/campo): dados ajudam a interpretar o significado dos valores
Tipo de dado (domínio): descreve os tipos de valores que podem ser exibidos na coluna
Grau (aridade): número de coluna na relação
Além disso, temos algumas características relevantes em relação a tuplas e atributos.
Ordenação de tuplas: não faz diferença
Valores em tuplas: a ordenação dos atributos/colunas pode ser relevante dependendo do nível de abstração.
Valores e nulls: Cada valor em uma tupla é um valor atômico (não divisível), logo os atributos compostos ou multivalorados não são permitidos. Entretanto, é possível, em regra (exceto a chave primária), os valores nulls.
No modelo relacional, os dados estão dispostos em tabelas (relações), assim as Operações de Álgebra Relacional é uma forma de manipular os dados que estão nas tabelas, dispostas em linhas (tupla) e colunas (atributo).
Operações de Álgebra Relacional
Continuando no Modelo Conceitual e Lógico para SEFAZ-SP, agora conheçamos os conceitos de “View” e “Indices”.
View: única tabela (virtual) que é derivada de outras tabelas (reais ou virtuais).
Indices (Index): estrutura de acesso utilizados para otimizar o desempenho de consultas a registros em uma base de dados relacional
Além disso, um tema extremamente importante é o conceito de chaves. Atenção total nesse ponto.
Chaves:
As Regras de Codd são um conjunto de critérios estabelecidos por Edgar F. Codd para definir um sistema de banco de dados relacional. Elas garantem consistência, integridade e padrões de operação em sistemas de gerenciamento de banco de dados relacionais.
Atente-se que é comum chamarmos de “12 Regras”, mas elas vão da 00 até a 12, logo são 13 regras.
12 Regras de Codd:
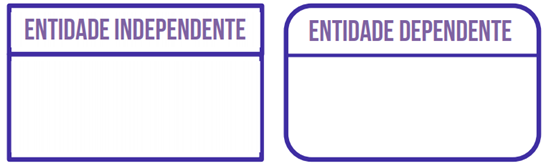
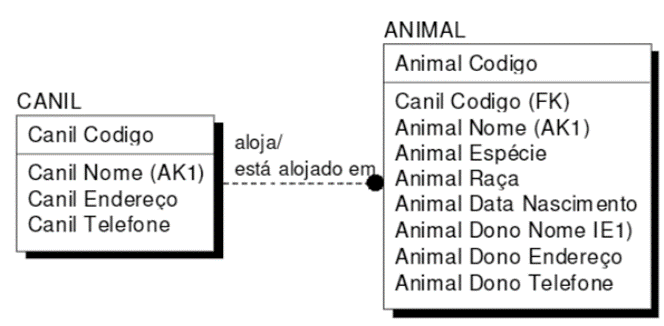
Para finalizar o sobre Modelo Conceitual e Lógico para SEFAZ-SP, vejamos a Notação IDEF1X (Integration Definition for Information Modeling), notação aplicada no modelo conceitual
As entidades são representadas da seguinte forma:
Enquanto nos relacionamentos,

Por fim, vejamos as entidades.
Pessoal, chegamos ao final do resumo sobre Modelo Conceitual e Lógico para SEFAZ-SP, tema muito importante para a prova, espero que tenha sido útil.
Assim, não deixe de estudar o assunto na íntegra por nossas aulas, além de treinar por meio de questões de concurso em nosso sistema de questões.
Gostou do artigo? Siga-nos
https://www.instagram.com/resumospassarin/
Prepare-se com o melhor material e com quem mais aprova em Concursos Públicos em todo o país!