Juliane Dionisio
Aprovada em 1° lugar no concurso TRT-10 para o cargo de Analista Judiciário - Especialidade: Arquivologia
Aprovada em 1° lugar no concurso TRT-10: Juliane Dionisio
Confira neste artigo uma análise sobre a Mineração de Dados (Data Mining) da disciplina de Tecnologia da Informação, para a prova da Polícia Federal (PF).

Olá, Estrategista. Tudo bem com vocês?
A área policial está bombando nesse ano de 2021. São dezenas de concursos, com alguns oferecendo mais de 1000 vagas, como é o caso do concurso da Polícia Federal.
A disciplina com o maior número de questões para esse certame é Tecnologia da Informação. Desse modo, estamos trazendo neste artigo um estudo sobre a Mineração de Dados, também conhecida como Data Mining, tópico bastante relevante para a prova da PF.
Assim, iremos abordar os seguintes tópicos neste artigo:
A Mineração de Dados, ou Data Mining, em inglês, é considerada como o processo de encontrar padrões e correlações úteis em uma grande quantidade de dados.
Através de técnicas de inteligência artificial, aprendizado de máquina, matemática, estatística, entre outras, é possível analisar grandes volumes de dados, de modo a prever resultados futuros por meio do descobrimento de padrões anteriormente desconhecidos.
Desse modo, é possível que uma empresa possa melhorar seus resultados em decorrência da utilização do Data Mining, por meio de corte de custos, aumento da lucratividade, melhora no relacionamento com os clientes, otimização de procedimentos, entre outras vantagens,
Muitos modelos foram desenvolvidos com o intuito de realizar uma mineração de dados bem sucedida, sendo que um dos principais é o CRISP DM (Cross Industry Standard Process for Data Mining – Processo Padrão Inter-Indústrias para Mineração de Dados).
Esse é um modelo não proprietário, o qual divide a mineração de dados em seis etapas:
Entendimento do Negócio: essa fase procura entender e compreender quais são os objetivos de negócio, bem como as necessidades e expectativas que a empresa está procurando alcançar através da mineração de dados. Com essas informações em mãos, a preparação é iniciada, especificando os responsáveis pelas coletas e análises dos dados, definindo o orçamento a ser utilizado, entre outras ações para iniciar a busca pelo conhecimento.
Entendimento de Dados: a partir desse momento, os dados brutos começam a ser identificados, através da coleta inicial, entendendo os pontos fortes e fracos, bem como as limitações do conjunto de dados, analisando a qualidade e o volume das informações que foram coletadas, etc.
Preparação dos Dados: essa fase também é chamada de pré-processamento, pois os dados brutos identificados na etapa antecedente começam a ser selecionados para a análise final, de modo a definir como eles serão utilizados para realizar a modelagem em si. É realizada a limpeza dos dados, retirando algumas inconsistências; são definidos os formatos e outras questões técnicas para a análise; há a inclusão de novas ferramentas de modelagem, entre outras ações. Essa fase é a que consome a maior parte do tempo do modelo CRISP DM.
Modelagem: com os dados a serem analisados totalmente prontos, são aplicadas as técnicas específicas de Data Mining, de acordo com os objetivos traçados na primeira fase. Diferentes técnicas podem ser utilizadas, a depender das necessidades estabelecidas, como a técnica de associação, agrupamento, classificação, entre outras.
Avaliação: esta fase é muito importante, pois ela avalia se os resultados gerados na modelagem realizada na etapa anterior condizem com as expectativas e com os objetivos traçados pela empresa na primeira etapa. Assim, como resultado desta fase, é decidido se o modelo está pronto para ser implementado ou se novas mudanças são necessárias, podendo haver a revisão de etapas anteriores.
Implantação: após a finalização das etapas anteriores, é realizada a apresentação do modelo pronto ao cliente, através de relatórios de resultados, por exemplo. Desse modo, o cliente já poderá iniciar a sua utilização, na prática, de todo o trabalho que foi realizado, com o intuito de alcançar os seus objetivos negociais.
Esse é o principal tema da Mineração de Dados, sendo muito importante para a prova da PF. Estas técnicas são as ações utilizadas para encontrar os padrões em um grande volume de dados. Estes padrões podem ser explicativos, de modo a descrever as relações entre segmentos de dados, ou preditivos, os quais podem prever valores futuros baseados em dados anteriores.
Iremos tratar neste artigo as três principais técnicas mais cobradas em concursos: classificação, agrupamento (ou clusterização) e associação.
Também chamada de Aprendizado Supervisionado, esta técnica é utilizada para realizar a predição de informações com base em um conjunto de classes pré-definidas. Em outras palavras, a classificação utiliza dados históricos e classes previamente definidas para descobrir um modelo que possa prever como será o comportamento dessas classes posteriormente.
Vamos exemplificar. Uma empresa de vendas pode utilizar o histórico de pagamentos que ela possui dos seus clientes para classificá-los em grupos de adimplência e inadimplência, definindo quais são considerados maus e bons pagadores.
O agrupamento, também chamado de clusterização ou análise de clusters, é uma técnica de Data Mining utilizada para classificar elementos e eventos em determinadas classes, chamadas de clusters. Desse modo, ao analisar essas classes, padrões úteis de conhecimento podem ser descobertos.
Os elementos dentro de cada classe são semelhantes entre si, porém, são diferentes quando comparados a itens de outras classes.
Um ponto que o diferencia da “Classificação” é que as classes do “Agrupamento” não são pré-definidas. Por exemplo, em um hospital, os pacientes de Covid-19 podem ser divididos de acordo com os sintomas apresentados não definidos previamente. Assim, podem ser encontrados padrões similares entre os integrantes de uma mesma classe de sintomas.
PARA FIXAR:
Classificação: utiliza classes definidas.
Agrupamento: utiliza classes não definidas.
Por fim, analisaremos a última técnica de mineração de dados deste artigo para o concurso da PF, a associação.
A associação utiliza algumas regras para desvendar relacionamentos entre variáveis, inclusive em situações em que elas, aparentemente, não possuem nenhuma relação. Esta técnica é muito utilizada em ambientes de vendas, de modo a descobrir os hábitos de consumo dos diferentes segmentos de clientes, bem como identificar relações entre a comercialização de diferentes produtos, com o intuito de maximizar as negociações das suas mercadorias. Por este motivo, esse modelo também é chamado de Análise de Cesta de Compras.
Por exemplo, já foi identificado uma inusitada relação entre as vendas de atum e pasta de dente. Isso acontece pois quando as pessoas comem atum, eles possuem uma tendência maior em escovar os dentes logo após a refeição.
A análise também pode ser realizada entre produtos mais óbvios, em que os clientes que procuram por macarrão muito provavelmente irão também comprar molho de tomate ou creme de leite e batata palha.
Duas medidas muito utilizadas na descoberta desses padrões são o Suporte e a Confiança.
O suporte é a fração das transações totais que contém os itens analisados. Ou seja, caso sejam dois elementos analisados, será a porcentagem de transações que inclui tanto A quanto B.
A confiança é a porcentagem de relação entre os itens analisados. Ou seja, é a frequência em que o item A aparece nas transações que contêm B.
Vamos ilustrar.
Suponha-se que sejam realizadas as seguintes compras abaixo por 10 clientes:
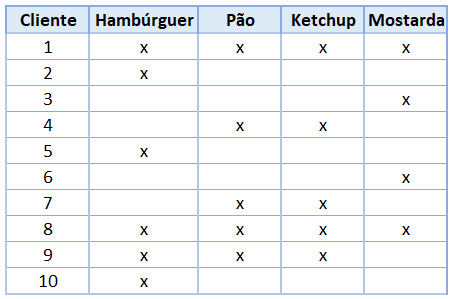
É a porcentagem das compras que possuem hambúrguer e pão, simultaneamente.
Nesse caso, são apenas 3 compras (1, 8 e 9). Como temos um total de 10 compras, então o suporte é de 3/10 = 30%.
É a frequência que aparece o pão nas compras em que estão presentes o hambúrguer.
A quantidade de compras em que o hambúrguer está presente é 6 (1, 2, 5, 8, 9 e 10). Dessas 6 compras, aparece o pão apenas em 3 (1, 8 e 9). Assim, a confiança é de 3/6 = 50%.
Desse modo, essa descoberta de padrões de associação pode ser utilizada para tomadas de decisões gerenciais.
Pessoal, chegamos ao fim deste estudo sobre a Mineração de Dados (Data Mining) da disciplina de Tecnologia da Informação, para o concurso da Polícia Federal (PF).
Procuramos realizar um resumo sobre as principais informações deste tópico, as quais possuem boas chances de serem cobradas na sua prova.
Veja este outro artigo O que priorizar nos seus estudos na reta final para a PF. Ele é uma importante análise sobre quais tópicos podem ser priorizados nesta reta final de estudos, mas sem deixar as demais de lado.
De modo a potencializar os seus estudos nesta reta final para o concurso da PF, com o material mais completo e com os melhores professores do mercado, acesse o site do Estratégia Concursos e confira os nossos cursos completos para a Polícia Federal.
Bons estudos e até a próxima!
Assinatura Anual Ilimitada*
Prepare-se com o melhor material e com quem mais aprova em Concursos Públicos em todo o país. Assine agora a nossa Assinatura Anual e tenha acesso ilimitado* a todos os nossos cursos.
ASSINE AGORA – Assinatura Ilimitada
Sistema de Questões
Estratégia Questões nasceu maior do que todos os concorrentes, com mais questões cadastradas e mais soluções por professores. Então, confira e aproveite os descontos e bônus imperdíveis!
ASSINE AGORA – Sistema de Questões
Fique por dentro dos concursos em aberto
As oportunidades previstas