Juliane Dionisio
Aprovada em 1° lugar no concurso TRT-10 para o cargo de Analista Judiciário - Especialidade: Arquivologia
Aprovada em 1° lugar no concurso TRT-10: Juliane Dionisio
Para quem estava com saudades, vamos retomar hoje os nossos artigos da área de Ciência de Dados, uma disciplina bastante cobrada de Tecnologia da Informação (TI). Nesta publicação, falaremos sobre Extract, Transform and Load (ETL) e Extract, Load and Transform (ELT).
Apesar da inversão das letras L / T parecer pequena, saiba que os processos podem ser bem diferentes na prática, com resultados distintos. A nossa missão hoje é explicar cada um deles, evidenciando suas diferenças. Veja agora o que teremos pela frente:
Sem dúvida, recomendamos a leitura deste artigo aos concurseiros de TI, principalmente aos que pretendem realizar provas específicas de Ciência de Dados. Não deixe de ler também caso esteja estudando para algum concurso concorrido da área geral, mesmo que o Edital não esteja ainda aberto.
Para facilitar e dinamizar os seus estudos, este artigo foi escrito em versão reduzida, sem perder a qualidade. Esperamos que você goste e consiga aproveitar ao máximo o conteúdo que preparamos. Vamos começar então.
Tempo de leitura aproximada: 5 a 10 minutos
Vamos começar o artigo de hoje com um exemplo bem simples. Observe isoladamente o número 39. O que ele representa? A idade de uma pessoa especial? A quantidade de pessoas em uma fila de espera? O número de uma casa?
Não há como saber, porque o dado é bruto. Não temos nenhuma outra pista que permita identificá-lo. O número 39 pode ser associado a uma série de coisas.
Suponha agora que complementamos o nosso exemplo com “Artigo 39”. Ficou mais fácil descobrir que estamos falando? Provavelmente, estamos no contexto do Direito, fazendo referência a um trecho de uma legislação (Lei Geral de Proteção de Dados Pessoais, por exemplo).
Ao incluir o termo “Artigo”, o dado bruto 39 passou a fazer sentido. Ele passa a ser considerado como informação. Isso é essencial para um processo de análise. Afinal, você prefere analisar dados soltos ou informações consolidadas em um relatório?
O processamento de dados é um dos mecanismos que apoia a análise mencionada. De forma simples, ele faz com os dados tornem-se mais organizados. Por conseguinte, eles passam a ter mais utilidade para quem os acessa, com sentido, significado, sendo vistos como informações.
Existem algumas abordagens para o processamento de dados. Neste artigo, vamos explicar o ETL e o ELT, que costumam ser alvo das bancas de concursos. Continue conosco, pois teremos mais conteúdo nas próximas seções.
Na Introdução, já demos um breve spoiler do que ETL significa a partir da expressão em inglês, mas agora vamos aprofundar. A sigla ETL representa extrair, transformar e carregar dados.
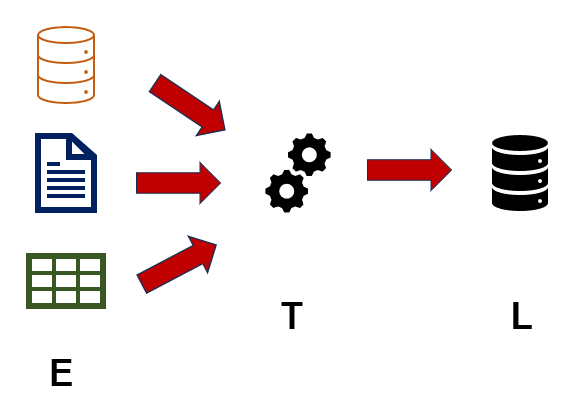
E = EXTRACT => Extrair dados brutos de diversas fontes (bases, documentos, planilhas etc.).
T = TRANSFORM => Transformar os dados extraídos, de acordo com a necessidade do negócio (limpeza de anomalias, padronização do formato, remoção de duplicatas etc).
L = LOAD => Carga dos dados transformados em uma base final (Data Warehouse, Data Mart etc.).
Você Sabia? Data Warehouse é uma espécie de base de dados consolidada das organizações, um grande depósito de dados. Data Mart é um subconjunto do Data Warehouse, geralmente para um departamento específico.
Apesar de parecer o contrário, o processamento no ETL não é rápido. O tempo de extração pode variar, principalmente se estamos lidando com um volume significativo de dados brutos, diante de uma rede lenta. Porém, o gargalo mesmo é a transformação.
No mundo real, as fontes contêm diversos problemas no cadastro dos dados (principalmente se eles são feitos por um usuário). Deixar os dados com a maior homogeneidade possível, a fim de facilitar futuras análises, pode ser bem custoso. É por isso que a transformação demora tanto.
Embora a carga não seja a vilã, ela sai prejudicada. Ela é uma etapa um pouco mais rápida que a transformação, mas que acaba sendo deixada para o final, pela própria abordagem do processo.
Se o problema do ETL é a transformação, que tal seria deixá-la por último? Será que o processamento ficaria mais rápido? A resposta é sim, concurseiro. A velocidade é a principal “bandeira” do ELT, que abordaremos agora.
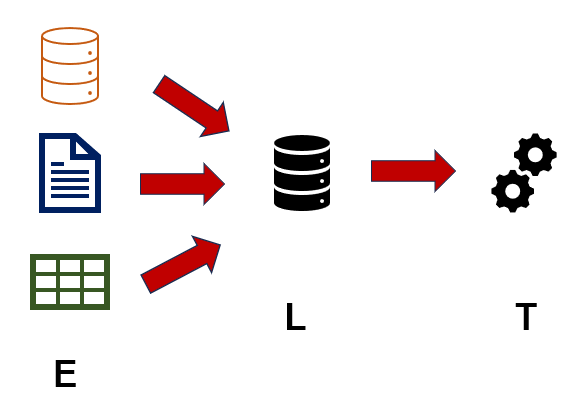
E = EXTRACT = Extrair dados brutos de diversas fontes (bases, documentos, planilhas etc.).
L = LOAD = Carga dos dados extraídos em um repositório consolidado (frequentemente um Data Lake).
T = TRANSFORM = Transformação dos dados de interesse carregados, de acordo com a necessidade do negócio (limpeza de anomalias, padronização do formato, remoção de duplicatas etc).
Você Sabia? Data Lake é um repositório centralizado para armazenar dados estruturados, semiestruturados e não estruturados. Se quiser saber mais, não deixe de ler o nosso artigo sobre o tema: https://www.estrategiaconcursos.com.br/blog/ciencia-dados-data-lake/.
A carga é efetivamente a etapa que vai disponibilizar os dados na base para consultas. Embora a transformação seja importante para trazer um refinamento, os dados podem ser acessados somente com a carga. Isso pode ser extremamente útil em situações urgentes, emergenciais.
A transformação também é diferenciada. Já parou para pensar que você não precisa transformar toda a base que foi carregada? Uma vez que a carga esteja feita, é possível transformar apenas uma parte dos dados que seja de interesse. Perceba que é uma abordagem diferente e bem mais rápida.
Além da agilidade, o ELT também é apropriado para atuação com grandes volumes de dados (Big Data). Hoje, dados não estruturados são a maioria. Nesse contexto, transformar apenas o necessário, depois de carregar, pode fazer muito mais sentido.
Você Sabia? Alguns exemplos de dados não estruturados são vídeos e áudios. Se você tem dúvidas sobre as classificações dos dados, leia o nosso artigo: https://www.estrategiaconcursos.com.br/blog/ciencia-de-dados-classificacoes-estruturas/.
Como sabemos que esse assunto pode ser um pouco “nebuloso” (especialmente se você está vendo os conceitos pela primeira vez), preparamos um quadro comparativo com as principais diferenças. Ele é uma espécie de resumo do que já falamos, com informações adicionais. Esperamos que ajude!
| ETL | ELT | |
|---|---|---|
| Etapas | Extração (1), Transformação (2) e Carga (3). | Extração (1), Carga (2) e Transformação (3). |
| Extração | Dados brutos de diversas fontes (bases, documentos, planilhas etc.). | Dados brutos de diversas fontes (bases, documentos, planilhas etc.). |
| Transformação | Dados extraídos, de acordo com a necessidade do negócio (limpeza de anomalias, padronização do formato, remoção de duplicatas etc). | Dados de interesse carregados, de acordo com a necessidade do negócio (limpeza de anomalias, padronização do formato, remoção de duplicatas etc). |
| Carga | Carga dos dados transformados em uma base final (Data Warehouse, Data Mart etc.). | Carga dos dados extraídos em um repositório consolidado (frequentemente um Data Lake). |
| Tempo de Processamento | Demora na transformação e, por conseguinte, na carga do processo. | Mais rápido, pois a carga é independente da transformação. Apenas os dados de interesse podem ser transformados. |
| Arquitetura e Infraestrutura | Necessidade de armazenamento menor, com solução mais simples, para arquiteturas on-premises (locais) e legadas. | Necessidade de armazenamento maior, com solução mais complexa, para arquiteturas em nuvem e escaláveis. |
| Custos | Mais caro, sem tanta flexibilidade na infraestrutura. | Mais barato, admitindo adaptações na infraestrutura. |
| Recomendações de Uso | Soluções mais simples, com repositórios menores, que não necessitem de agilidade. | Soluções mais complexas, com repositórios maiores, que necessitem de agilidade. |
Em suma, este artigo apresentou um resumo de ETL e ELT, um dos temas de destaque da área de Ciência de Dados. Se você concluiu a leitura e entendeu os conceitos, o próximo passo será realizar muitas questões para sedimentar o aprendizado.
Historicamente, alunos aprovados realizam várias baterias de exercícios e simulados para atingir seu objetivo. O acesso ao Sistema de Questões do Estratégia Concursos é feito pelo link: https://concursos.estrategia.com/.
Além disso, não esqueça de retornar ao tópico de tempos em tempos para fazer revisões. Aproveite o quadro comparativo disponibilizado neste artigo para isso, pois irá ajudá-lo nesta jornada.
Por fim, para aprofundar o conteúdo ou tirar dúvidas específicas, busque o material do Estratégia Concursos. Nós oferecemos diversos cursos em pdf, videoaulas e áudios para você ouvir onde quiser. Saiba mais por meio do link: http://www.estrategiaconcursos.com.br/cursos/.
Bons estudos e até a próxima!
Cristiane Selem Ferreira Neves é Bacharel em Ciência da Computação e Mestre em Sistemas de Informação pela Universidade Federal do Rio de Janeiro (UFRJ), além de possuir a certificação Project Management Professional pelo Project Management Institute (PMI). Já foi aprovada nos seguintes concursos: ITERJ (2012), DATAPREV (2012), VALEC (2012), Rioprevidência (2012/2013), TJ-RJ (2022), TCE-RJ (2022) e CGE-SC (2022/2023). Atualmente exerce o cargo efetivo de Auditora de Controle Externo – Tecnologia da Informação e integra o corpo docente da Escola de Contas de Gestão do TCE-RJ, além de ser produtora de conteúdo dos Blogs do Estratégia Concursos, OAB e Carreiras Jurídicas.