Saudações colegas concurseiros, no artigo de hoje analisaremos uma cobrança de um tópico novo na área de Machine Learning, o kernel do SVM.
Sabemos que a cobrança de inteligência artificial em concursos, seja por qualquer forma, como “análise de dados”, “machine learning”, “sistemas de suporte à decisão analítica” etc. não é mais uma promessa, mas uma realidade.
Além de já serem uma exigência comum em concursos específicos para cientistas de dados, conhecimentos em aprendizado de máquina tornaram-se comuns em concursos de tecnologia da informação em geral.
Porém, recentemente, essa cobrança se estendeu até mesmo a áreas que tradicionalmente não estavam diretamente ligadas à tecnologia, como concursos para cargos de Auditor Fiscal.
Ocorre que, conforme a exigência desse tema se consolida, as bancas vão explorando novos assuntos em suas provas.
Em questão ultra recente, do concurso da IPEA – Instituto de Pesquisa Econômica Aplicada -, a CESGRANRIO inovou e cobrou um tópico inédito: o kernel do SVM.
Então, visando ajudar aos concurseiros, nesse artigo iremos revisar o algoritmo SVM, abordar o que seria o kernel do SVM e tentar prever uma cobrança futura a respeito de outro tema ainda não cobrado, o “kernel trick”.
Support Vector Machine (SVM)
Regra geral, a Support Vector Machine(ou Máquina de Vetores de Suporte, traduzido do inglês) é um algoritmo aplicado para realizar classificação binária, isto é, visa prever se determinada característica está ou não contida nos dados.
Cuidado que esse algoritmo também pode ser utilizado para outras tarefas, como regressão ou previsão de outliers, por exemplo. Porém, nesse artigo, abordaremos sua aplicação usual, ou seja, a de classificação.
Pois bem, quando treinamos uma SVM estamos procurando uma função linear que melhor separa os dados, isto é, que maximiza a sua distância aos pontos de dados mais próximos de cada classe.
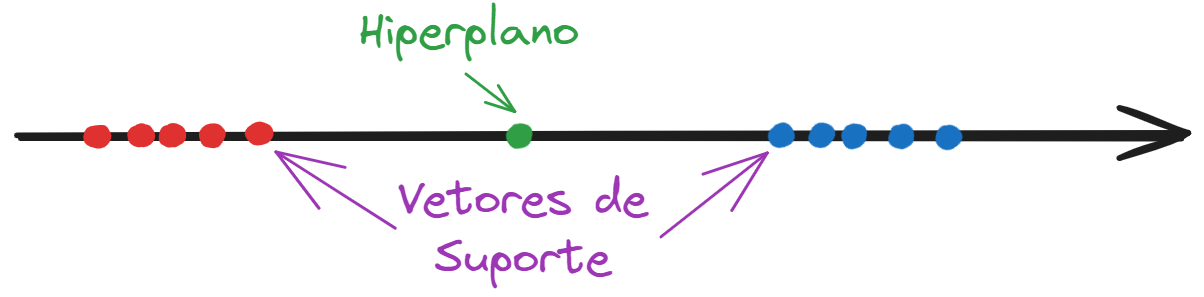
Vejamos, então, a seguir, em um gráfico uma SVM treinada que encontrou uma função linear (no caso de um gráfico em uma dimensão como o nosso, é um ponto, pintado de verde) que melhor separa os dados em duas classes (os pontos do tipo azul dos pontos do tipo vermelho).
Vejam também que a maior distância possível do classificador em verde aos pontos mais próximos de cada classe está desenhada em amarelo.
Assim, fica demonstrado que a SVM foi capaz de classificar os dados separando a reta em duas regiões: os pontos à esquerda do ponto verde são do tipo vermelho, enquanto os pontos à direita são do tipo azul.
Finalmente, para concursos, precisávamos saber que a função linear encontrada (isto é, o ponto verde) pela Máquina de Vetor de Suporte se chama hiperplano e que os pontos de cada classe que definiram a maior distância possível se chamam vetores de suporte.
Kernel do SVM
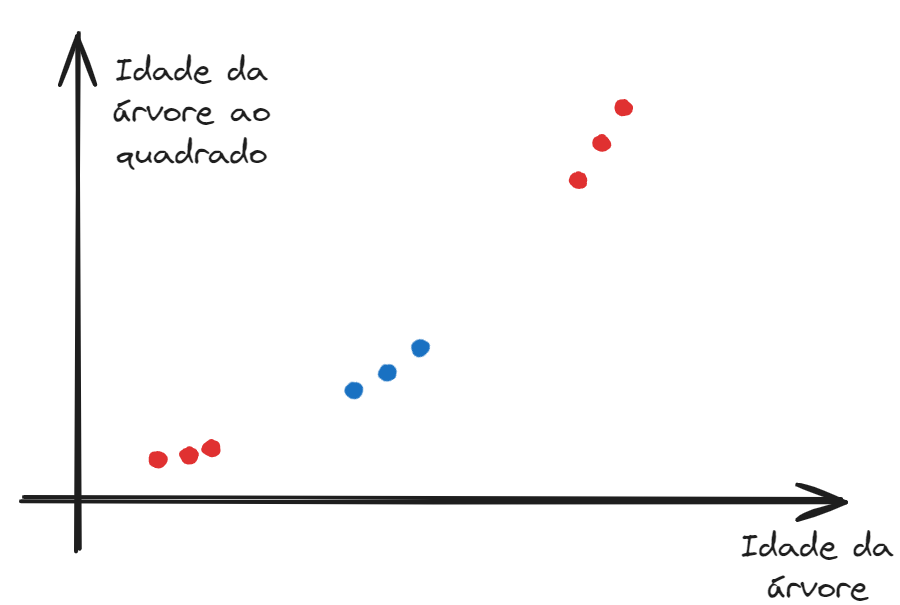
Porém, pode acontecer de os dados não serem passíveis de separação por uma função linear, como, por exemplo, ao tentarmos determinar se uma árvore é adequada para a fabricação de lápis.
Sabemos que árvores muito jovens ou muito antigas (indicadas pelos pontos vermelhos no gráfico a seguir) não são adequadas para o corte, sendo que a idade ótima se situa em um período intermediário (indicada pelos pontos azuis no gráfico a seguir).
Vejam que aqui não há forma de se inserir um ponto verde de forma a separar os dados em duas categorias distintas, isto é, em pontos “à esquerda” e “à direita” do classificador, sem misturarmos pontos vermelhos e azuis.
Para resolver esse problema, o russo Vladimir Vapnik com outros pesquisadores propuseram que, se inserirmos novas características aos pontos, podemos os transformar em dados linearmente separáveis.
Assim, utilizaram uma função matemática para inserir novas informações aos pontos chamada de kernel, que , por estarmos aplicando no contexto das Support Vector Machines, chamamos de kernel do SVM.
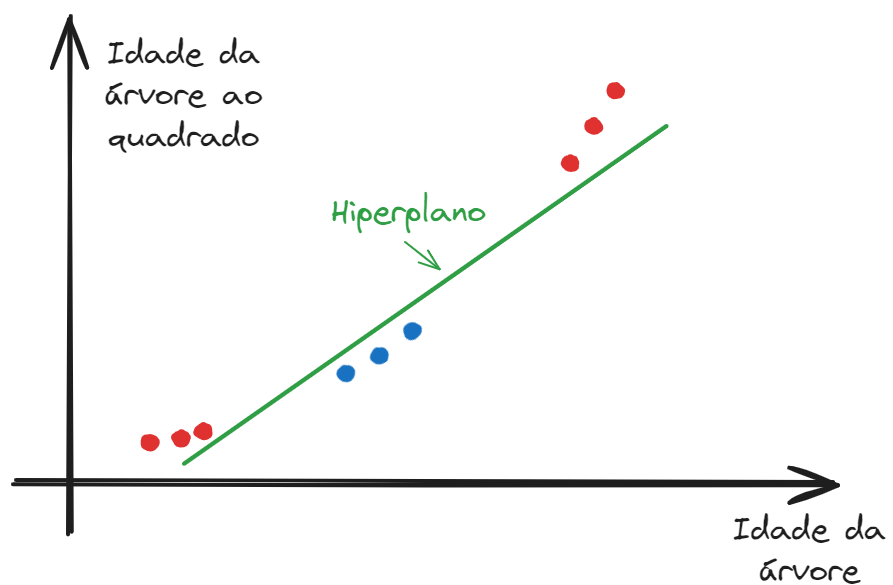
Dessa forma, introduzindo tal técnica ao nosso exemplo, poderíamos aplicar uma função kernel que simplesmente eleva as idades das árvores ao quadrado. Assim, ao aplicarmos esse kernel específico aos pontos, faremos com que tenham duas informações: suas idades e suas idades ao quadrado.
Vejamos como fica o novo gráfico com esses pontos transformados, então.
Agora tomem cuidado que nosso hiperplano linear em um ambiente em duas dimensões não é mais um ponto, mas uma reta!
Assim, vejam que nesse momento temos pontos possíveis de serem separados por um hiperplano.
Kernel Trick – Além do Kernel do SVM!
Agora vamos tentar prever uma cobrança ainda não realizada em concursos públicos.
Vimos que a função kernel adiciona aos pontos novas informações a partir das suas características originais. Porém, na prática, esse cálculo que adiciona novas informações aos dados originais é muito custoso e pode inviabilizar a aplicação do método.
Dessa forma, visando tornar esse método computacionalmente eficiente, aplica-se um “macete” matemático chamado de kernel trick (trick, em tradução do inglês, significa truque).
Sem entrar em maiores cálculos matemáticos (que envolvem conhecimento de álgebra linear), com o kernel trick evitamos a necessidade de calcular explicitamente as novas coordenadas dos pontos, tornando o problema em um com baixo custo computacional.
Ou seja, o kernel trick nada mais é que uma simplificação matemática que permite calcular implicitamente no espaço o necessário para que os pontos sejam linearmente separáveis.
Conclusão
A presença crescente de inteligência artificial e aprendizado de máquina em concursos públicos no geral é um reflexo do papel cada vez mais relevante dessas tecnologias na nossa sociedade.
Essa tendência é evidenciada por sua cobrança em áreas tradicionalmente não associadas à tecnologia, como concursos para cargos de Auditor Fiscal.
Ocorre que as bancas estão estendendo a cobrança no tema para tópicos novos, sendo que tivemos um exemplo recente disso no concurso do Instituto de Pesquisa Econômica Aplicada (IPEA), onde a CESGRANRIO introduziu um tópico inédito: o kernel do SVM.
Isso demonstra como as bancas examinadoras estão se adaptando e explorando novos assuntos para avaliar o conhecimento dos candidatos, nos obrigando a mantermos atualizados.
E agora, querido aluno, consegue resolver a famigerada questão?
(CESGRANRIO/IPEA/2024) Em um projeto de ciência de dados para análise preditiva no setor bancário, um cientista de dados precisa escolher tecnologias de aprendizado de máquina adequadas para classificar clientes com base no risco de inadimplência.
Considerando-se a intenção de lidar com dados não linearmente separáveis por meio do uso de um kernel, qual é o algoritmo mais adequado para essa tarefa?
(A) Análise de Componentes Principais
(B) Árvore de Decisão
(C) K-Means
(D) Máquina de Vetores de Suporte
(E) Regressão Logística
Gabarito: D
Instagram: @prof.lucas.ianni
Quer aprender mais? Estamos com um curso em pós edital para o CNU (Bloco 2 – Tecnologia, Dados e Informação) Conhecimentos Específicos – Eixo Temático 5 – Apoio à Decisão e Inteligência Artificial – 2024. Vejam:
Prepare-se com o melhor material e com quem mais aprova em Concursos Públicos em todo o país. Assine agora a nossa Assinatura Anual e tenha acesso ilimitado* a todos os nossos cursos.