
Tipo de dados numéricos do PostgreSQL
Prezados,
Começamos hoje uma ação de comentários das questões de banco de dados e BI das provas mais recentes de concursos de TI. Nossa ideia é comentar uma prova por semana. Quem quiser sugerir uma prova recente pode me mandar a prova e o gabarito para o meu e-mail. Farei o possível para atender todas as demandas.
Vamos começar pela prova aplicada no dia 21 de fevereiro de 2016. A prova do TRT-MT. São apenas seis questões, mas estão devidamente comentadas abaixo! Espero que gostem!
29. Um Analista está desenvolvendo um Modelo Entidade-Relacionamento do banco de dados de um tribunal sob uma perspectiva lógica e parte do modelo é formado pelas duas entidades abaixo, relacionadas com cardinalidade n:m.
A entidade Processo contém os atributos:
– NuM_Seq (número sequencial do processo por unidade de origem) – valor inteiro – (PK).
– Dig (dígito verificador) – valor inteiro – (PK).
– Ano (ano do ajuizamento) – valor inteiro – (PK).
– Org (órgão ou segmento do Poder Judiciário, sendo 5 o correspondente à Justiça do Trabalho) – valor inteiro.
– Tribunal (tribunal do segmento do Poder Judiciário, sendo 23 para o TRT da 23a Região) – valor inteiro (FK).
– Origem (unidade de origem do processo, sendo 4 zeros para o TRT) – valor inteiro.
A entidade Advogado contém os atributos:
– Num_OAB (número da OAB) – cadeia de caracteres – primary key.
– Nome (nome do advogado) – cadeia de caracteres.
– Telefone (telefone residencial e comercial) – cadeia de caracteres.
Considerando que Advogado acompanha Processo,
(A) o atributo Num_OAB precisa aparecer também na entidade Processo, como chave estrangeira, para garantir a integridade referencial entre os dados.
(B) o relacionamento não pode ser n:m, pois em cada Processo não se pode referenciar mais do que um Advogado para cada uma das partes, logo, trata-se de um relacionamento 1:n.
(C) o atributo Tribunal não pode ser chave estrangeira na entidade Processo, pois dos Tribunais não há necessidade de se cadastrar nada além do número.
(D) na implementação das tabelas, o relacionamento n:m deverá ser dividido em duas relações 1:n e uma nova tabela deverá ser criada para representar o relacionamento.
(E) como a relação é n:m, os atributos chave primária da entidade Processo devem aparecer na entidade Advogado como chave estrangeira e vice-versa.
Comentário: Questão interessante! Veja que estamos falando de um modelo entidade relacionamento (ER) com duas entidades e um relacionamento classificado como n:m entre elas.
Ao transformar ou traduzir o modelo ER para o modelo relacional vamos fazer uso de uma regra descrita em um artigo publicado por mim recentemente aqui no estratégia. Precisamos criar uma nova tabela com as chaves primárias de cada uma das entidades juntamente com os atributos do relacionamento. A questão na fala de atributos que fazem parte do relacionamento, sendo assim vamos focar apenas nas chaves primárias (PK).
Analisando o caso concreto, vamos criar uma tabela Advogado_Processo com os atributos Dig, Ano, Org e Num_OAB. Os três primeiros fazem parte da chave primária composta da entidade Processo, já o último é chave primária simples da entidade Advogado.
Com base no exposto até aqui, podemos concluir que a única alternativa que propõe uma construção correta para as tabelas do modelo relacional, tomando por referência o modelo ER em questão, está na alternativa D.
Gabarito: D
30. Considere a instrução abaixo, digitada em um banco de dados Oracle 11g que possui a tabela Produtos, aberta e em condições ideais, contendo os campos
NomeProduto – varchar2(50),
PrecoUnitario – number(5,2),
UnidadesEmEstoque – integer,
UnidadesNoPedido – integer:
SELECT NomeProduto, PrecoUnitario*(UnidadesEmEstoque + I (UnidadesNoPedido,0)) FROM Produtos;
Para retornar 0 se o valor de UnidadesNoPedido for nulo, a lacuna I deverá ser corretamente preenchida com
(A) IIF
(B) IFNULL
(C) NVL
(D) COALESCE
(E) ISNULL
Comentário: Essa questão exige o entendimento de cada uma das funções do Oracle listadas nas alternativas. Apenas para vocês terem ideia de onde a questão foi tirada, basta clicar aqui.
O IIF executa um teste condicional e retorna um valor numérico apropriado ou um conjunto dependendo se o valor avaliado é verdadeiro ou falso. Vejam a sintaxe do comando abaixo:
IIF ( search_condition, true_part, false_part )
O IFNULL() não existe dentro do contexto do Oracle, ele é usado pelo MySQL para especificar como vamos tratar os valores nulos. Ele retorna zero caso o valor da coluna seja nulo.
O NVL() é a função do Oracle que tem o mesmo objetivo, ele também retorna zero caso o valor da coluna seja nulo.
A função COALESCE recebe dois ou mais argumentos e retorna o primeiro que não é nulo. Vejam que essa função também pode ser gabarito da questão. O examinador tirou a questão do site acima e não verificou se o Oracle possuía essa função. Acho que caberia recurso, não sei se alguém entrou! Espero que sim!
O ISNULL() não existe dentro do contexto do Oracle, ele é usado pelo Microsoft SQL Server para especificar como vamos tratar os valores nulos. Ele retorna zero caso o valor da coluna seja nulo.
Gabarito: C ou D.
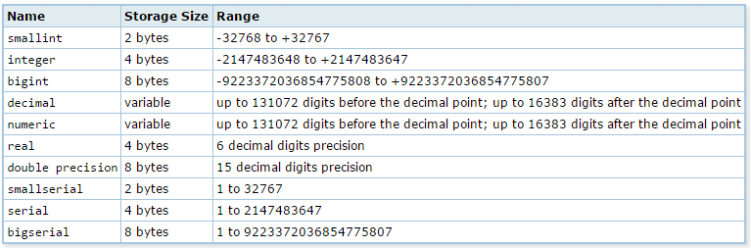
31. São vários os tipos de dados numéricos no PostgreSQL. O tipo
(A) smallint tem tamanho de armazenamento de 1 byte, que permite armazenar a faixa de valores inteiros de -128 a 127.
(B) bigint é a escolha usual para números inteiros, pois oferece o melhor equilíbrio entre faixa de valores, tamanho de armazenamento e desempenho.
(C) integer tem tamanho de armazenamento de 4 bytes e pode armazenar valores na faixa de -32768 a 32767.
(D) numeric pode armazenar números com precisão variável de, no máximo, 100 dígitos.
(E) serial é um tipo conveniente para definir colunas identificadoras únicas, semelhante à propriedade auto incremento.
Comentário: A questão trata dos tipos de dados numéricos do PostgreSQL. Observem abaixo uma tabela com os tipos numéricos presentes no PostgreSQL:
Tipo de dados numéricos do PostgreSQL
Vejam que os tipos decimal e numeric têm o tamanho de armazenamento variável. Outra novidade apresentada acima são os tipos smallserial, serial e bigserial utilizados para valores auto incrementados, cujos domínios só permitem valores positivos.
Agora vamos aos erros das alternativas. Na letra A diz que smallint tem 1 byte, ao invés de 2. Na alternativa B, fala que o bigint é uma alternativa intermediária, quando na realidade ele é o valor numérico que possui o maior range. A assertiva C afirma erroneamente que integer possui apenas 2 bytes, quando na realidade apresenta 4. Por fim, a letra E diz que decimal tem precisão de 100 dígitos, quando na realidade podemos ter até 16383 dígitos depois da casa decimal.
E a alternativa E? Essa é a nosso resposta, apresenta o tipo serial, que são utilizados para definir colunas identificadoras únicas, semelhante à propriedade auto incremento.
Gabarito: E
32.Um Analista digitou as instruções abaixo em uma ferramenta de backup disponível para um determinado Sistema Gerenciador de Banco de Dados – SGBD.
CONFIGURE CONTROLFILE AUTOBACKUP ON;
CONFIGURE RETENTION POLICY TO RECOVERY WINDOW OF 2 DAYS;
BACKUP INCREMENTAL LEVEL 0 DATABASE;
DELETE NOPROMPT OBSOLETE;
Trata-se da ferramenta
(A) SQL Backup Manager – SBM para PostgreSQL.
(B) Recovery Manager – RMAN para Oracle.
(C) Server Manager Backup – SMB para SQL Server.
(D) Export Logical Backup − ELB para Oracle.
(E) Data Pump Export − EXPDP para Oracle.
Comentário: O comando acima é bem característico de um backup feito pelo utilitário RMAN da Oracle. Na primeira linha você define o valor o backup automático para o arquivo de controle. A segunda linha define uma política de retenção que estabelece o número de dias entre o momento atual e o ponto de recuperação mais recente. “Essa política especifica que o RMAN deve reter todos os backups (baseado no tempo) durante um determinado X número de dias antes de torná-los obsoletos. A questão que devemos fazer ao optar por essa política é perguntar por quanto tempo queremos manter os backups para que seja possível uma recuperação em qualquer período em um tempo no passado (em dias) dentro da janela de retenção.”
A próxima linha define o tipo de backup que queremos fazer: incremental level 0. O backup incremental diferencial registra todos os blocos alterados tendo como referência o último backup incremental, seja ele um backup incremental Nivel-0 ou Nivel-1. No Oracle, quando fazemos backups utilizando o RMAN, além da opção do backup FULL, temos também a opção de utilizarmos os backups incrementais. No RMAN, o termo “backup incremental” é utilizado para fazer referência a dois tipos: incremental diferencial e incremental cumulativo. O backup incremental inicial é conhecido como backup Nivel-0 (nível zero). Cada backup incremental realizado após o inicial é chamado de backup Nivel-1 (nível um).
Na última linha fazemos uma referência ao comando DELETE, neste contexto ele vai remover backups não utilizáveis. O comando utiliza dois parâmetros: NOPROMT e OBSOLETE. O NOPROMPT exclui arquivos especificados sem primeiro listar os arquivos ou solicitar confirmação. O comando DELETE NOPROMPT ainda exibe cada item quando ele é excluído. Por padrão, DELETE exibe uma lista de arquivos a serem excluídos e solicita confirmação. Se o usuário confirma, o RMAN mostra cada item quando ele é excluído. Se você estiver executando os comandos a partir de um arquivo, então, NOPROMPT é o padrão.
Em relação ao OBSOLETE, ele elimina backups e cópias de arquivo de dados gravados no repositório RMAN que estão obsoletos, ou seja, que não são mais necessários. Além dos arquivo de backup de dados obsoletos, RMAN exclui logs arquivados obsoletos e backups do log arquivados. RMAN determina quais backups e cópias de arquivos de dados não são mais necessários, que por sua vez determina quando os logs (e backups de logs) não são mais necessários.
Gabarito: B
33.Após um DBA criar um usuário executando a instrução
CREATE USER Paulo IDENTIFIED BY abcd;
,o usuário Paulo ainda não tem nenhum privilégio. Para conceder a ele o privilégio de sistema para criar tabelas e views o DBA deve digitar no Oracle 11g, a instrução:
(A) CREATE PERMISSION create table, create view TO Paulo;
(B) CREATE GRANT table, view TO Paulo;
(C) GRANT create table, create view TO Paulo;
(D) CREATE ROLE create table, create view TO Paulo;
(E) GRANT OPTION create table AND create view TO Paulo;
Comentário: Se pensarmos no SQL padrão podemos fazer uso do comando DCL de GRANT para dar permissão a criação de tabelas e visões. Neste caso a única alternativa que apresenta a sintaxe correta do comando é a alternativa C. As demais possuem erros de sintaxe.
Gabarito: C
34.Na abordagem Star Schema, usada para modelar data warehouses, os fatos são representados na tabela de fatos, que normalmente
(A) é única em um diagrama e ocupa a posição central.
(B) está ligada com cardinalidade n:m às tabelas de dimensão.
(C) está ligada às tabelas de dimensão, que se relacionam entre si com cardinalidade 1:n.
(D) tem chave primária formada independente das chaves estrangeiras das tabelas de dimensão.
(E) está ligada a outras tabelas de fatos em um layout em forma de estrela.
Comentário: A última questão da nossa prova de hoje trata da ementa vista pelo curso de BI. O examinador testa seus conhecimentos sobre modelagem dimensional, mais especificamente, sobre o modelo star schema. O modelo em questão é composto por uma tabela fato e um conjunto de tabelas dimensão. Em outras palavras, cada processo de negócio é representado por um modelo dimensional que consiste em uma tabela fato contendo medições numéricas do evento e, cercada por um conjunto de tabelas dimensão que contêm o contexto no momento em que ocorreu o evento. Vejam que ela ocupa uma posição central no modelo, o que leva a nossa resposta, na alternativa A.
Gabarito: A
Espero que tenham gostado! Não deixem de mandar suas críticas e perguntas nos comentários!
Forte abraço,
Thiago Cavalcanti



A Assinatura Vitalícia do Estratégia Concursos está de volta, mas pode ser pela última vez!…
O deputado estadual Jari Oliveira solicitou ao secretário de Estado da Casa Civil autorização para…
Será que vem novo concurso público para a Secretaria Estadual de Educação do Rio de Janeiro (Seeduc…
Atenção, corujas: vem aí um novo concurso SES PE (Secretaria de Saúde de Pernambuco). Isso…
Olá, pessoal, tudo bem? Neste artigo trataremos acerca da ADI 7236, a qual suspendeu liminarmente…
O Instituto Federal do Mato Grosso do Sul (IFMS) publicou dois novos editais! Um para…
Ver comentários
Olá, gostei muito da ideia, e de suas explicações também!
Se puder, eu gostaria de ver a resolução das questões de BD da prova de Técnico Judiciário - Programação de Sistemas do TRE-PI realizada no dia 31/01/16.
Abraço.