Abaixo comentamos a prova do IBGE referente ao cargo de web mobile (8 questões). Vamos a elas.
Considere uma tabela relacional R(A1, A2, … , An) que, depois de normalizada, foi decomposta num esquema com três tabelas, R1, R2 e R3. Nesse caso, diz-se que a decomposição ocorreu sem perda quando:
(A) todas as dependências funcionais existentes para os atributos de R1, R2, R3 são preservadas em R;
(B) qualquer instância de R pode ser recuperada a partir de junções de R1, R2 e R3;
(C) nenhuma das tabelas R1, R2 e R3 contém todos os atributos de R;
(D) todas as tabelas R1, R2 e R3 possuem chaves primárias;
(E) a soma do número de atributos de cada tabela R1, R2 e R3 é maior que o número de atributos de R.
Comentário: Questão interessante sobre dependências funcionais (DF). Quando estudamos o conteúdo observamos que as decomposições feitas até a forma normal de Boyce-Codd feitas sem perdas. Isso quer dizer basicamente que a partir das relações resultantes da decomposição é possível, geralmente por meio de junções, recriar ou obter cada uma das tuplas da relação original.
Ao analisarmos as alternativas observamos que a letra B apresenta um texto coerente com o explicado no parágrafo anterior. As demais alternativas não tratam da decomposição sem perdas na junção. Por exemplo, a alternativa A fala que todas as DF devem ser preservadas, embora em uma decomposição feita por meio do processo de normalização, as DF são de fato preservadas, isso não tem relação com as possíveis perdas.
Sinceramente, eu gostei bastantes desta questão! Parabéns pra FGV
Gabarito: B
Na derivação de dependências funcionais num projeto relacional, está correto afirmar que se
A,B –> X,Y
então é certo que:
(A) A –> X
(B) A –> X,Y
(C) X,Y –> A
(D) A,B –> X
(E) X,Y –> A,B
Comentário: Outra questão de dependência funcional. Não vejo necessidade e cobrar tanto esse assunto numa prova. Mas vejam que ele define no enunciado uma DF entre os atributos A, B, X e Y, qual seja, A,B à X,Y. Quando você ver uma definição desta, você pode pensar que se esses atributos e somente eles fazem parte de uma relação A, B é uma chave composta. Sendo assim o conjunto de atributos determina tanto X quanto Y, separadamente. Isso é o que vemos na alternativa D.
Gabarito: D
Considere as seguintes características de um projeto de banco de dados.
I. O modelo de dados é conhecido a priori e é estável;
II. A integridade dos dados deve ser rigorosamente mantida;
III. Velocidade e escalabilidade são preponderantes.
Dessas características, o emprego de bancos de dados NoSQL é favorecido somente por:
(A) I;
(B) I e II;
(C) II;
(D) II e III;
(E) III.
Comentário: Veja que a questão trata das propriedades ou características de um projeto de banco de dados NoSQL. Sabemos que bancos de dados deste tipo substituem a sigla ACID (atomicidade, consistência, isolamento e durabilidade) que está relacionado com transações pela sigla BASE que está relacionada com os conceitos de BA – (Basically Available) disponibilidade é prioridade, S – (Soft-State) – Não precisa ser consistente o tempo todo e E – (Eventually Consistent) – Consistente em momento indeterminado. Outro ponto importante é a relação de NoSQL com o modelo de dados, geralmente o banco é considerado schema free, ou seja, livre de esquema ou de um modelo pré-determinado a priori.
Partindo desta exposição básica sobre NoSQL podemos analisar as alternativas I, II e III. Vejam que as duas primeiras são definições associadas a banco de dados relacionais ou transacionais. A alternativa III trata de outro aspecto que não vimos ainda, mas que também está relacionada ao conceito de NoSQL e Big Data. NoSQL é uma tecnologia que trouxe o foco de banco de dados para performance e escalabilidade. A pergunta é como analisar uma grande quantidade de dados.
Gabarito: E
No MySQL, o comando SQL
select *
from T
order by A desc limit 4,8
provoca:
(A) a ordenação dos oito primeiros registros de T, como especificado, e a exibição dos quatro primeiros registros na ordem;
(B) a ordenação dos registros de T, como especificado, e a exibição dos quatro primeiros registros, pois o segundo parâmetro é ignorado;
(C) a ordenação dos registros de T, como especificado, e a exibição dos registros nos quais o valor de A está entre 4 e 8;
(D) a ordenação dos registros de T, como especificado, e a exibição de oito registros a partir do quarto, na ordem;
(E) a ordenação dos quatro primeiros registros de T a partir do oitavo, como especificado, e a exibição desses, na ordem.
Comentário: Essa questão foi resolvida em um periscope alguns dias atrás. Se você ainda não me segue no periscope, baixe o aplicativo, temos encontros semanais para falar de banco de dados e business intelligence para concursos.
O comando SELECT descrito no enunciado demonstra que o resultado obtido deve ver ordenado pelo atributo A. Em seguida, é usado a sintaxe da clausula LIMIT com dois atributos, neste caso, o primeiro representa o OFFSET ou deslocamento, nele os primeiros registros são descartados do resultado da consulta. O próximo parâmetro apresenta a quantidade de tuplas que serão retornadas pela consulta, neste caso específico temos oito registros. Desta forma, podemos observar que nossa resposta se encontra na alternativa D.
Gabarito: D
Analise o comando de definição de um trigger no SQL Server.
create trigger TR_LOG
ON Empresa
FOR INSERT
AS
insert into log(usuario,datahora,evento)
select current_user,getdate(),
‘Inseriu ‘ + codemp
from inserted
Quando o trigger TR_LOG é acionado, é necessário que:
(A) insert seja uma das tabelas do mesmo banco de dados da tabela empresa;
(B) codemp seja uma coluna da tabela empresa;
(C) codemp seja uma função definida pelo usuário;
(D) log seja uma stored procedure que receba uma tabela como parâmetro;
(E) somente um registro tenha sido inserido pelo comando insert que disparou o trigger.
Comentário: Observando a sintaxe do comando, encontramos alguns elementos conhecidos, após a cláusula ON definimos que o trigger será criado sobre a tabela EMPRESA para eventos de INSERT. Quando um registro é inserido na tabela, o TRIGGER vai inserir dentro da tabela log os valores respectivos para usuário, datahora e evento. Vejam que INSERTED é uma tabela que armazena cópias das linhas da tabela EMPRESA afetadas pelo INSERT e codemp deve ser uma coluna da tabela EMPRESA. Partindo do exposto, podemos marcar nossa resposta na alternativa B.
Gabarito: B
No SQL Server, considere uma função criada como exibido a seguir.
create function FF
(@data as smalldatetime = ’01/01/2001′)
returns int
BEGIN
RETURN convert(int , @data)
END
O comando que utiliza a função FF incorretamente é:
(A) select dbo.FF(’12/12/2015′)
(B) select a + dbo.FF(10) from R
(C) select * from dbo.FF(20)
(D) select * from (select dbo.FF(20) x) x
(E) select * from R order by dbo.FF(10)
Comentário: A resposta desta questão é um pouco intuitiva, vejam que o retorno da função é um escalar ou inteiro. Para que seja respeitado o padrão sintático do SQL é necessário que o elemento presente na cláusula FROM seja uma relação ou tabela. Desda forma não podemos utilizar o resultado de uma função que retorna um valor como é o caso da alternativa C. Percebam que existe um artifício técnico para garantir que a função seja chamada, ele está presente na alternativa D. Usamos o comando SELECT que, pela definição da linguagem deve retornar outra relação, para que a sintaxe não seja comprometida.
Gabarito: C
Os comandos SQL
create table R (a int, b int)
create table S (c int, d int)
insert into R values(1,2)
insert into R values(2,3)
insert into R values(2,3)
insert into R values(3,5)
insert into R values(4,1)
insert into S values(1,2)
insert into S values(2,1)
insert into S values(2,3)
insert into S values(3,5)
select r.a , r.b from R
where not exists
(select * from S where s.c=r.a and s.d=r.b)
Produzem um resultado que, além da linha de títulos, contém:
(A) uma linha;
(B) duas linhas;
(C) três linhas;
(D) quatro linhas;
(E) cinco linhas.
Comentário: Após a execução dos comandos de insert acima temos os seguintes valores nas tabelas R e S.
R (1,2) (2,3) (3,5) (4,1)
S (1,2) (2,1) (2,3) (3,5)
A consulta pede que para cada elemento do conjunto R, verificarmos se o resultado da segunda consulta é vazio, caso seja, retorne no resultado da consulta. A consulta interna verifica de o valor do campo a de R é igual ao valor do campo c de S, e se o valor do campo b de R é igual ao valor do campo d de S. Vejam que se existir essa igualdade o valor será retornado na consulta interna, o que impede que a consulta externa seja verdadeira. Em outras palavras, estamos procurando os pares de R que não estão em S, ou seja, o par (4,1).
Gabarito: A
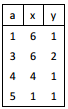
O comando SQL
select a, sum(b) x, COUNT(*) y
from T
group by a
produz como resultado as linhas abaixo.
Na tabela T, composta por duas colunas, a e b, nessa ordem, há um registro duplicado que contém os valores:
(A) 1 e 3
(B) 3 e 3
(C) 3 e 6
(D) 4 e 2
(E) 5 e 1
Comentário: Essa é uma questão interessante. Vejam que os valores mostrados na tabela é o resultado da consulta. Desta forma sabemos que a coluna x é o resultado de uma soma e que a coluna y é o resultado da contagem dos elementos com o mesmo valor, ou seja, das linhas duplicadas. Podemos perceber que o registro duplicado é o que tem valor de y maior do que 1. E que o para esse registro para a coluna a é 3, que é o mesmo valor que aparece na função de agrupamento; e b é também igual a 3 pois o valor da coluna x é a soma dos valores dos dois registros. Devemos portando dividir o valor por 2. Assim, chegamos a nossa resposta na alternativa B.
Gabarito: B
Ficamos por aqui, em breve voltamos com os comentários das outras provas do IBGE para cargos de TI.
Forte abraço,
Thiago Rodrigues Cavalcanti
Facebook: https://www.facebook.com/profthiagocavalcanti/
Periscope: Prof. Thiago Cavalcanti




Os servidores da Petrobras iniciaram uma greve nesta quarta-feira (26), com duração de 24 horas,…
Concurso TCE SP passa por sua primeira retificação Foi dada a largada para as inscrições…
Oi pessoal!! Neste texto vamos analisar um assunto muito importante para a prova de Auditor…
Nesta quarta-feira (26), o edital do concurso TCE SP (Tribunal do Contas do Estado de…
O novo concurso público da Polícia Federal (PF) será organizado pelo Cebraspe? De acordo com…
Novo concurso PF está autorizado com vagas para Agente, Delegado, Escrivão, Papiloscopista e Perito! Temos…