Marcos Medeiros da Silva
Aprovado em 13° lugar no concurso PF para o cargo de Agente de Polícia Federal
Aprovado na PF: Marcos Silva
Questões : ANAC (BANCA: ESAF)
Apresentamos abaixo as questões da prova da ANAC devidamente comentadas para o cargo de ANALISTA ADMINISTRATIVO DE TI.
Assinale a opção correta relativa a banco de dados.
a) Modelos de Dados de Baixo Nível independem de conceitos relativos a percepções dos usuários.
b) Modelos de Dados de Alto Nível oferecem conceitos que são próximos como usuários percebem os dados.
c) Modelos de Dados de Alto Nível oferecem conceitos de como gestores realizam consultas operacionais.
d) Modelos de Dados de Baixo Nível prescindem de conhecimentos especializados para sua construção.
e) Modelos de Dados de Alto Desempenho oferecem conceitos de como usuários estabelecem a efetividade de requisitos.
Comentário: Nesta questão vamos procura descrever um pouco como é feita a classificação dos modelos de dados. Uma das primeiras taxonomias aceitas pela literatura especializada divide os modelos em baixo e alto nível. Essa estratificação esta balizada pelo nível de abstração do modelo. Quanto mais abstrato, menor o nível de detalhamento, mais fácil dos usuários entenderem os modelos. Esse modelo é conhecido como modelos de alto nível.
Na outra ponta, modelos que descrevem detalhes físicos da implementação do modelo de dados possuem especificidades que são necessárias apenas para administradores de banco de dados. São definições associadas aos perfis técnicos de suporte. Esses são os modelos de dados de baixo nível.
Em ambos os casos os modelos são um conjunto de ferramentas conceituais para a descrição dos dados e dos relacionamentos existentes entre eles, da semântica e das restrições que atuam sobre estes.
Os modelos de dados de alto nível são por vezes conhecidos como modelos de dados conceituais, como falamos eles oferecem conceitos mais próximos ao entendimento dos usuários, um exemplo seria o modelo entidade relacionamento. Na outra ponta, existe o modelo de baixo nível ou físico que descreve como os dados são armazenados fisicamente no computador.
Entre os modelos conceitual e físico existe um modelo de implementação que oferece conceitos que podem ser facilmente utilizados por usuários finais, mas não estão distantes da maneira pela qual os dados estão organizados dentro do computador, um exemplo seria o modelo relacional.
Após o entendimento dos conceitos acima podemos encontrar uma definição precisa na alternativa B: “b) Modelos de Dados de Alto Nível oferecem conceitos que são próximos como usuários percebem os dados.”
Gabarito: B
Os dados de um banco de dados, em determinado instante, são chamados de
a) conjunto atual de ocorrências ou instâncias.
b) conjunto atualizado de acessos ou instantes.
c) conjunto dinâmico de consistências ou instâncias.
d) subconjunto de ocorrências equivalentes.
e) conjunto ordenado de instâncias ocorridas.
Comentário: Existem dois conceitos que devem ser compreendidos para a resolução desta questão: instância e esquema.
A coleção de informações armazenadas no banco de dados em um determinado momento é chamada de instância do banco de dados. O projeto geral do banco de dados é chamado de esquema de banco de dados. Os esquemas não mudam com frequência.
Desta forma, podemos observar que as ocorrências ou instâncias em um determinado momento referem-se aos dados do banco de dados. Isso nos leva a resposta na alternativa A.
Gabarito: A
São etapas do Projeto de Banco de Dados Relacional:
a) Mapeamento de tipos de entidade regular. Mapeamento de tipos de entidade fraca. Mapeamento dos tipos de relacionamento binário 1:1. Mapeamento de tipos de relacionamento binário 1:N. Mapeamento de tipos de relacionamento binário M:N. Mapeamento de atributos multivariados. Mapeamento de tipos de relacionamento n-ário.
b) Mapeamento de instâncias regulares. Mapeamento de tipos de entidade externa. Mapeamento dos tipos de relacionamento binário 1:1. Mapeamento de tipos de relacionamento binário 1:N. Mapeamento de tipos de relacionamento binário M:N. Mapeamento de atributos multirredundantes. Mapeamento de tipos de relacionamento n-ário.
c) Mapeamento de tipos de entidade regular. Mapeamento de tipos de entidade interna. Mapeamento dos tipos de relacionamento binário 1:1. Mapeamento de tipos de relacionamento binário 1:N2. Mapeamento de tipos de constantes binárias. Mapeamento de atributos multivariados. Mapeamento de tipos de relacionamento n-tupla.
d) Mapeamento de tipos de entidade prevalente. Mapeamento de tipos de entidade secundária. Mapeamento de tipos de atributo binário 1:1. Mapeamento de tipos de atributo binário 1:N. Mapeamento de tipos de atributo binário M:N. Mapeamento de instâncias multivariadas. Mapeamento de tipos de atributo n-ário.
e) Mapeamento de tipos de entidade regular 1:1. Mapeamento de tipos de entidade 1:N. Mapeamento dos tipos de relacionamento binário numérico. Mapeamento de tipos de relacionamento binário alfanumérico. Mapeamento de tipos de relacionamento lógico. Mapeamento de atributos multivariados. Mapeamento de tipos de relacionamento normalizado.
Comentário: Essa questão foi retirada do artigo que publiquei aqui no estratégia alguns dias atrás. Para não copiar o artigo inteiro, sugiro que você leia aqui o texto completo. Após conhecer o passo a passo para transformação de um modelo ER em relacional, você vai perceber a resposta na alternativa A.
Gabarito: A
O ciclo de vida do sistema de aplicação de banco de dados inclui:
a) Atualização do sistema. Projeto do banco de dados. Planejamento do banco de dados. Carga ou conversão de dados. Restrição de aplicações. Validação e disseminação. Operação. Monitoramento e manutenção.
b) Segmentação do sistema. Projeto do banco de dados. Implementação de consultas ao banco de dados. Implementação de conversores de dados. Conversão de aplicação. Teste e validação. Operação. Mapeamento e manutenção.
c) Definição do sistema. Projeto da sistemática de consultas ao banco de dados. Interpretação do banco de dados. Carga de teste de dados. Conversão de aplicação. Validação de sistema. Inicialização. Monitoramento e manutenção.
d) Definição do sistema. Especificação física de requisitos. Implementação de dados de instâncias. Carga de dados criptografados. Conversão de atributos. Teste e validação. Operação. Monitoramento e manutenção.
e) Definição do sistema. Projeto do banco de dados. Implementação do banco de dados. Carga ou conversão de dados. Conversão de aplicação. Teste e validação. Operação. Monitoramento e manutenção.
Comentário: Essa questão foi retirada de uma conjunto de passos conhecidos como ciclo de vida do desenvolvimento de banco de dados (Database development life cycle (DDLC)). Podemos observar esse ciclo na figura abaixo. Basta traduzir os termos em cada uma das etapas para obtermos a sequência correta, presente na alternativa E.
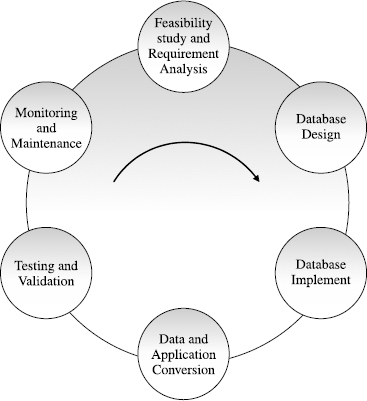
Gabarito: E
Em SQL, algumas consultas precisam de que os valores existentes no banco de dados sejam buscados e depois usados em uma condição de comparação. Elas podem ser formuladas por meio de consultas.
a) concorrentes.
b) comparadas.
c) segmentadas.
d) hierarquizadas.
e) aninhadas.
Comentário: Uma consulta SQL é aninhada quando ela está dentro de outra consulta SQL. A consulta aninhada normalmente aparece como parte de uma condição nas cláusulas WHERE ou HAVING. As consultas aninhadas também podem ser utilizadas na cláusula FROM.
As consultas aninhadas podem ser utilizadas como um procedimento em que a consulta é executada apenas uma vez, conhecida como não correlacionada. Outra opção é a consulta ser executada repetidas vezes, neste caso falamos que ela é correlacionada.
Gabarito: E
São objetivos da Mineração de Dados:
a) Distribuição, Identificação, Organização e Otimização.
b) Previsão, Priorização, Classificação e Alocação.
c) Previsão, Identificação, Classificação e Otimização.
d) Mapeamento, Identificação, Classificação e Atribuição.
e) Planejamento, Redirecionamento, Classificação e Otimização.
Comentário: A questão não foi muito feliz no enunciado, dentro da literatura especializada geralmente não usamos o termo “objetivo” para os conceitos apresentados na resposta. Mineração de Dados é um campo interdisciplinar que junta técnicas de máquinas de conhecimentos, reconhecimento de padrões, estatísticas, banco de dados e visualização, para conseguir extrair informações de grandes bases de dados.
Dentro deste cenário descrevemos uma lista de tarefas possíveis e técnicas para atingir nossos objetivos. Algumas dessas tarefas são listadas nas alternativas. A mineração de dados é comumente classificada pela sua capacidade em realizar determinadas tarefas.
A lista apresentada na questão é retirada do livro do Navathe, ele classifica as tarefas em categorias de problemas: previsão, identificação, classificação e otimização. Vejam o texto abaixo.
O objetivo específico da mineração de dados é o uso de algoritmos e estruturas de dados para alcançar uma das seguintes categorias de solução de problemas: predição, identificação, classificação ou otimização. A predição se refere à possibilidade de previsão do comportamento de determinados atributos ao longo do tempo, tal como o impacto que a descontinuidade da venda de um produto pode causar na venda de outro. Determinados padrões podem ser usados no reconhecimento de um item, evento ou atividade. Este reconhecimento pode se dar na identificação de fraudes, no uso de cartões de crédito. Grandes redes de varejo precisam estabelecer categorias de consumidores. A classificação é usada neste caso. A otimização é um problema típico da pesquisa operacional que pode ser abordado na mineração de dados, na busca do melhor uso de recursos limitados, tal como o espaço nas prateleiras das lojas do varejo.
Desta forma podemos encontrar nossa resposta na alternativa C.
Gabarito: C
Assinale a opção correta relativa a Sistema de Georreferenciamento.
a) São tipos de análise para dados espaciais: medidas, análise de interfaces, análise de local, análise de tempo.
b) Um banco de dados espacial passa por verificação de convergência para armazenar dados relacionados a espaços de objetos e de processos.
c) São tipos de análise para dados espaciais: melhorias espaciais, análise de fluxo, localização de interfaces, gestão de terreno.
d) Um banco de dados espacial é otimizado para armazenar e comutar dados relacionados a objetos não dimensionais.
e) Um banco de dados espacial é otimizado para armazenar e consultar dados relacionados a objetos no espaço, incluindo pontos, linhas e polígonos.
Comentário: A questão trata de dois conceitos os tipos de dados espaciais e os objetivos de um banco de dados espacial. Os tipos de analise espacial são:
Eventos ou Padrões Pontuais: fenômenos expressos por pontos. Ex: ocorrências de crimes, doenças, localização de espécies vegetais.
Superfícies Contínuas: estimadas por conjunto de amostras de campo resultantes de levantamento de recursos naturais. Ex: mapeamento geológico, topográfico, fitogeográfico.
Áreas com contagens e taxas agregadas: associados a levantamentos populacionais, censos (originalmente dados individuais agregados em unidades de análise).
Os banco de dados espaciais tem uma estrutura de funcionamento semelhante a dos bancos relacionais convencionais. Sua principal diferença é suportar feições geométricas em suas tabelas.
Dados geográficos existem em 3 formas básicas: dados de mapa que incluem diversos recursos geográficos de objetos (pontos, linhas e polígonos), dados de atributo que correspondem à dados descritivos que os sistemas SIG associam à recursos de mapa e dados de imagem que incluem dados como imagens de satélite e fotografias aéreas.
Desta forma podemos assinalar nossa resposta na alternativa E.
Gabarito: E
Big Data é:
a) volume + variedade + agilidade + efetividade, tudo agregando + valor + atualidade.
b) volume + oportunidade + segurança + veracidade, tudo agregando + valor.
c) dimensão + variedade + otimização + veracidade, tudo agregando + agilidade
d) volume + variedade + velocidade + veracidade, tudo agregando + valor.
e) volume + disponibilidade + velocidade + portabilidade, tudo requerendo – valor.
Comentário: Embora o termo “big data” seja relativamente novo, o ato de recolher e armazenar grandes quantidades de informações para eventual análise de dados é bem antigo. O conceito ganhou força no início dos anos 2000, quando um analista famoso deste setor, Doug Laney, articulou a definição de big data como os três Vs:
Volume. Organizações coletam dados de uma grande variedade de fontes, incluindo transações comerciais, redes sociais e informações de sensores ou dados transmitidos de máquina a máquina. No passado, armazenar tamanha quantidade de informações teria sido um problema – mas novas tecnologias (como o Hadoop) têm aliviado a carga.
Velocidade. Os dados fluem em uma velocidade sem precedentes e devem ser tratados em tempo hábil. Tags de RFID, sensores, celulares e contadores inteligentes estão impulsionado a necessidade de lidar com imensas quantidades de dados em tempo real, ou quase real.
Variedade. Os dados são gerados em todos os tipos de formatos – de dados estruturados, dados numéricos em bancos de dados tradicionais, até documentos de texto não estruturados, e-mail, vídeo, áudio, dados de cotações da bolsa e transações financeiras.
Outros Vs foram adicionados ao longo dos anos:
Veracidade. O quarto V do conceito está ligado à veracidade do conteúdo. Nem todos os dados gerados possuem consistência dentro do contexto. É preciso destacar o que é rico e correto em conteúdo no meio de tanta informação. Ao garantir essa separação, que é possível fazer a partir do Big Data, o que sobra são conhecimentos importantes para compreender melhor a entidade analisada ou o negócio em questão.
Valor. Para garantir que o trabalho dos outros Vs tragam retorno, é preciso gerar valor para os resultados que retornam do Big Data. Assim, aparece o último V do conceito.
Juntando todos os conceitos acima, chegamos a nossa resposta na alternativa D.
Gabarito: D
Para o processamento de grandes massas de dados, no contexto de Big Data, é muito utilizada uma plataforma de software em Java, de computação distribuída, voltada para clusters, inspirada no MapReduce e no GoogleFS. Esta plataforma é o(a)
Comentário: Questão inspirada na WIKIPEDIA:
Hadoop é uma plataforma de software em Java de computação distribuída voltada para clusters e processamento de grandes massas de dados. Foi inspirada no MapReduce e no GoogleFS (GFS). Trata-se de um projeto da Apache de alto nível, que vem sendo construído por uma comunidade de colaboradores utilizando em sua maior parte a linguagem de programação Java, com algum código nativo em C e alguns utilitários de linha de comando escrito utilizando scripts shell. Assim podemos marcar nossa resposta na alternativa D.
Gabarito: D
Qualquer dúvida estou as ordens,
PS: Não deixem de assistir nosso periscope semanal de banco de dados, toda quarta-feira, 21h.
Thiago Cavalcanti