| Gabarito oficial (preliminar) | |||
| 061 – D | 066 – D | 071 – A | 076 – E |
| 062 – B | 067 – B (Recurso) | 072 – A | 077 – E |
| 063 – C | 068 – A (Recurso) | 073 – C | 078 – B |
| 064 – C | 069 – D (Recurso) | 074 – D | 079 – D |
| 065 – E | 070 – C | 075 – C | 080 – B |
Atenção: Para responder às questões de números 61 a 68, considere as informações abaixo.
Suponha que um Auditor foi encarregado de modelar e criar um banco de dados para um pequeno sistema de pedidos de produtos de informática. Para realizar essa tarefa, desenvolveu o modelo mostrado na figura abaixo.

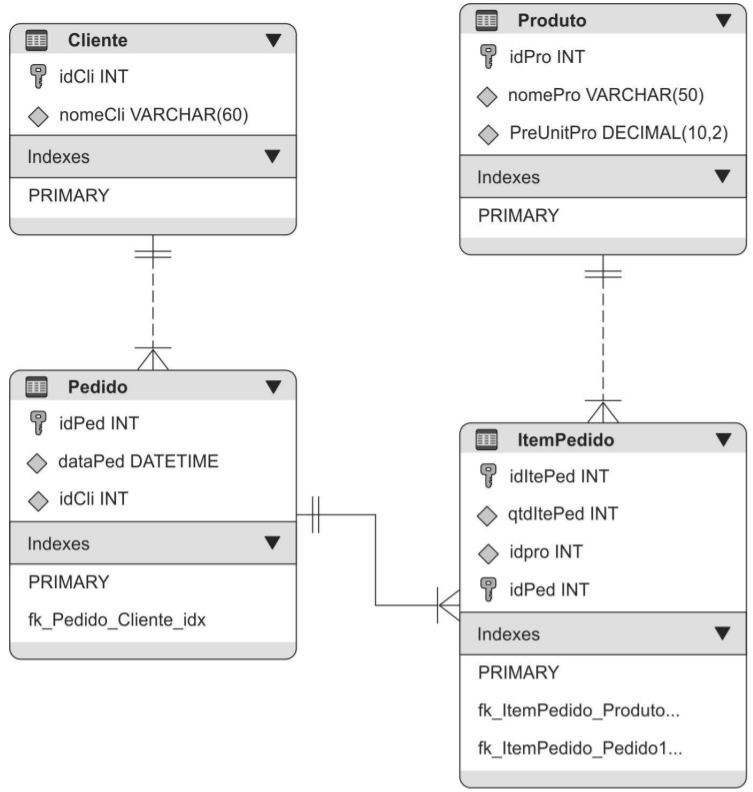
Após criar o modelo, implementou o banco de dados em um Sistema de Gerenciamento de Banco de Dados, criou as tabelas e cadastrou as seguintes informações:

Considere que o Auditor digitou um comando para inserir os valores abaixo na tabela ItemPedido.
idItePed qtdItePed idPed idPro
2 500 7 14
A mensagem correta que traduzirá o resultado da operação é
(A) you have an error in your SQL syntax.
(B) out of range value for column ‘qtdItePed’.
(C) cannot add a child row: a foreign key constraint fails.
(D) duplicate entry ‘2-7’ for key ‘PRIMARY’.
(E) register successfully – 1 row(s) affected.
Comentários: Observe que essa questão trata de uma das características principais de banco de dados relacionais: duas linhas não podem ter valores idênticos na chave primário. Na questão o Auditor tenta inserir uma nova linha cujo valor da chave primária, neste caso uma chave primária composta pelos atributos IdItePed e idPed, já existe entre os registros da tabela. Logo, o sistema de gerenciamento de banco de dados, ao tentar inserir essa linha vai apresentar um erro ao usuário (duplicate entry ‘2-7’ for key ‘PRIMARY’). Apenas por curiosidade as mensagens acima estão associadas ao MySQL.
Gabarito: D.
No modelo apresentado a entidade ItemPedido
(A) possui chave primária composta, mas não possui chave estrangeira, logo, não garante integridade referencial.
(B) possui uma chave primária composta pelos atributos idItePed e idPed, sendo que os atributos qtdItePed e idPro possuem dependência funcional completa com relação à chave primária.
(C) deveria conter o campo PreUniPro, pois o preço unitário do produto deve ser incluído em cada item do pedido.
(D) está relacionada com as entidades Pedido e Produto usando a notação Integrated DEFinition for Information Modelling − IDEF1X.
(E) possui relação com cardinalidade n:n com a entidade Produto e 1:n com a entidade Pedido.
Comentário: Essa questão vale a pena comentar todas as alternativas. Veja que na letra A, o examinador considerou corretamente a existência de uma chave primária composta. Contudo, ele errou ao afirmar que não existem chaves estrangeiras. Observe no diagrama original que existem duas chaves estrangeiras (IdPed e Idpro). Elas serão responsáveis por garantir a integridade referencial. Logo, essa não é a nossa resposta.
A alternativa B fala que a chave primária composta é dada por idItePed e idPed e que os demais atributos possuem dependência funcional total da chave primária. Podemos observa na tabela ItemPedido que esse fato está correto. Outra opção é entender que cada pedido pode ter vários itens. Neste caso, podemos visualizar a relação itemPedido como uma entidade fraca, veja que ela tem um valor sequencial para cada item da nota mais o identificador do pedido. O que diferencia uma linha da outra é o par de valores dos atributos que compõe a chave. Veja ainda que esse par vai determinar univocamente o produto e a sua quantidade em um pedido específico. Logo, temos a nossa resposta na alternativa B.
Não precisaríamos do preço neste caso. Já temos o idPro. Logo, para descobrirmos o preço basta fazermos uma junção utilizando os valores das duas relações. Logo, a alternativa C está incorreta.
O modelo IDEF1X usa vários aspectos diferentes dos que são apresentados na figura. Primeiramente IDEF1X separa os atributos chaves dos demais por uma linha dentro do retângulo. Outro ponto é que o modelo não utiliza a notação de pé-de-galinha para expressar a cardinalidade entre as entidades. Logo, temos uma alternativa errada. Você pode observar alguns conceitos básicos de IDEF1X nesta imagem.
Por fim, temos a cardinalidade do modelo, neste caso representado pela notação pé-de-galinha. A relação em questão se relaciona com cardinalidade 1:N com cada uma das outras duas, ou seja, possui relação com cardinalidade 1:n com a entidade Produto e 1:n com a entidade Pedido.
Gabarito: B
O Auditor tentou incluir os dados abaixo na tabela Pedido.
idPed dataPed idCli
13 2018-07-22 12
Ao executar a operação de inclusão, ocorreu um erro porque
(A) já existe um pedido criado para o cliente 12.
(B) não existe um pedido cadastrado com id 13.
(C) não há um cliente com id 12 cadastrado na tabela Cliente.
(D) já existe um pedido cadastrado com id 13.
(E) a data cadastrada não existe, já que o formato correto é dd/mm/yyyy.
Comentário: Veja que neste caso o examinador verifica seu conhecimento sobre integridade referencial. Quando vamos incluir um novo registro na tabela pedido devemos associá-lo a um cliente já existente na nossa base de dados. Neste caso, o cliente cujo idCli é igual a 12 não existe entre as tuplas da relação cliente. Logo, temos nossa resposta na alternativa C.
Gabarito: C
Se na entidade ItemPedido fosse adicionado o atributo valorTotalItem e nesse atributo fosse armazenado o resultado da multiplicação do valor contido no atributo qtdItePed da entidade ItemPedido pelo valor contido no atributo PreUniPro da entidade Produto, a entidade ItemPedido violaria
(A) todas as formas normais.
(B) as regras de integridade referencial.
(C) a terceira forma normal (3FN).
(D) a segunda forma normal (2FN).
(E) a primeira forma normal (1FN).
Comentário: Neste caso teríamos uma dependência transitiva. Observe que (idItePed, idPed) à (qtdItePed, PreUniPro) à valorTotalItem. Mas professor, neste caso PreUniPro não faz parte da relação, como podemos estabelecer essa transitividade? Precisamos pensar que idPro, que existe como atributo em ItemPedido, determina o PreUniPro. Logo, a inclusão deste novo campo levaria a um problema com a terceira forma normal. Assim, nossa resposta encontra-se na alternativa C.
Gabarito: C
Considere e avalie as asserções a seguir e a relação proposta entre elas.
I. O relacionamento entre as entidades Pedido e ItemPedido é um relacionamento identificado
PORQUE
II.idPed, que é chave estrangeira na entidade ItemPedido, faz parte da chave primária desta entidade.
É correto afirmar que
(A) a primeira asserção é uma proposição verdadeira, e a segunda, uma proposição falsa.
(B) tanto a primeira quanto a segunda são proposições falsas.
(C) as duas asserções são proposições verdadeiras, mas a segunda não é justificativa correta da primeira.
(D) a primeira asserção é uma proposição falsa, e a segunda, uma proposição verdadeira.
(E) as duas asserções são proposições verdadeiras, e a segunda é uma justificativa correta da primeira.
Comentário: Observe que estamos falando que ItemPedido é uma entidade fraca e que, para construir uma relação baseada nesta entidade precisamos pegar emprestado o atributo chave da entidade Pedido. Neste caso, estamos diante de um relacionamento identificador ou identificado. O fato é que a chave primária de Pedido vai compor a chave primária da relação ItemPedido. Logo, ambas as alternativas estão corretas e a segunda é justificativa para a primeira. Isso nos leva a resposta na alternativa E.
Gabarito: E
Atenção: As informações a seguir devem ser utilizadas para responder às questões de números 66 e 67.
O Auditor digitou um comando que exibiu os dados abaixo.
(A) SELECT idPed, idItePed, idPro, nomePro, qtdItePed, PreUnitPro, (ip.qtdItePed * pro.PreUnitPro) as “Total” FROM Produto, ItemPedido WHERE ip.idPro = pro.idPro AND ip.idPed <=3 ORDER BY ip.idPed;
(B) SELECT ip.idPed, ip.idItePed, ip.idPro, pro.nomePro, ip.qtdItePed, pro.PreUnitPro, SVG(ip.qtdItePed * pro.PreUnitPro) as “Total” FROM Produto pro, ItemPedido ip WHERE ip.idPro = pro.idPro AND ip.idPed <=3 ORDER BY ip.idPed;
(C) SELECT ip.idPed, ip.idItePed, ip.idPro, pro.nomePro, ip.qtdItePed, pro.PreUnitPro, (ip.qtdItePed * pro.PreUnitPro) as Total FROM Produto pro, ItemPedido ip WHERE ip.idPro = pro.idPro OR ip.idPed <=3 ORDER BY ip.idPed;
(D) SELECT ip.idPed, ip.idItePed, ip.idPro, pro.nomePro, ip.qtdItePed, pro.PreUnitPro, (ip.qtdItePed * pro.PreUnitPro) as Total FROM Produto pro, ItemPedido ip WHERE ip.idPro = pro.idPro AND ip.idPed <=3 ORDER BY ip.idPed;
(E) SELECT ip.idPed, ip.idItePed, ip.idPro, pro.nomePro, ip.qtdItePed, pro.PreUnitPro, (ip.qtdItePed * pro.PreUnitPro) as Total FROM Produto pro, ItemPedido ip WHERE ip.idPro = pro.idPro && ip.idPed
Comentário: Observe que essa questão pede que o concurseiro construa uma junção entre duas tabelas. Contudo o examinador optou por não usar o comando JOIN e fazer uma junção usando o produto cartesiano seguido por um predicado. Esse predicado vou fazer o papel da condição de junção estabelecendo um relacionamento entre os valores idProd presentes nas respectivas colunas das relações Produto e ItemPedido. Vejamos o código da resposta:
SELECT ip.idPed, ip.idItePed, ip.idPro, pro.nomePro, ip.qtdItePed, pro.PreUnitPro, (ip.qtdItePed * pro.PreUnitPro) as Total — lista as colunas que vão aparecer no resultado.
FROM Produto pro, ItemPedido ip — faz o produto cartesiano entre as relações.
WHERE ip.idPro = pro.idPro — condição de junção na cláusula WHERE
AND ip.idPed <=3 — restrição sobre os valores do atributo idPed
ORDER BY ip.idPed; — ordenação, de forma ascendente, pelo atributo idPed.
Assim, temos nossa resposta na alternativa D.
Gabarito: D.
Se o Auditor usasse join, o comando correto para exibir os dados seria
(A) JOIN ip.idPed, ip.idItePed, ip.idPro, pro.nomePro, ip.qtdItePed, pro.PreUnitPro, (ip.qtdItePed * pro.PreUnitPro) as Total FROM Produto pro, ItemPedido ip WHERE ip.idPro = pro.idPro AND ip.idPed <=3 ORDER BY ip.idPed;
(B) SELECT ip.idPed, ip.idItePed, ip.idPro, pro.nomePro, ip.qtdItePed, pro.PreUnitPro, (ip.qtdItePed * pro.PreUnitPro) as Total FROM Produto pro JOIN ItemPedido ip ON ip.idPro = pro.idPro AND ip.idPed <=3 ORDER BY ip.idPed;
(C) SELECT JOIN ip.idPed, ip.idItePed, ip.idPro, pro.nomePro, ip.qtdItePed, pro.PreUnitPro, (ip.qtdItePed * pro.PreUnitPro) as Total FROM Produto pro, ItemPedido ip WHERE ip.idPro = pro.idPro AND ip.idPed <=3 ORDER BY ip.idPed;
(D) JOIN ip.idPed, ip.idItePed, ip.idPro, pro.nomePro, ip.qtdItePed, pro.PreUnitPro, (ip.qtdItePed * pro.PreUnitPro) as Total ON Produto pro, ItemPedido ip WHERE ip.idPro = pro.idPro AND ip.idPed <=3 ORDER BY ip.idPed;
(E) SELECT idPed, idItePed, dPro, nomePro, qtdItePed, reUnitPro, (qtdItePed * PreUnitPro) as Total FROM Produto pro JOIN ItemPedido ip WHERE ItemProduto.idPro = Produto.idPro AND ItemProduto.idPed <=3 ORDER BY idPed;
Comentário: Nesta questão o examinador optou por usar a sintaxe mais consistente e otimizada para execução de uma junção. Lembre-se que a palavra chave JOIN aparece dentro da cláusula FROM. Logo, podemos eliminar essas alternativas que apresentam o JOIN no início do comando. Outro ponto é a necessidade da condição de junção dada pela cláusula ON ou USING. Observa-se, então, que a única alternativa que possível o ON é a letra B. Contudo, a letra B apresenta um problema de sintaxe. O examinador “esqueceu” de colocar a cláusula WHERE após a condição de junção. Isso gera um erro na maioria dos SGDBs e não é o padrão definido pelo SQL. O correto seria:
SELECT ip.idPed, ip.idItePed, ip.idPro, pro.nomePro, ip.qtdItePed, pro.PreUnitPro, (ip.qtdItePed * pro.PreUnitPro) as Total
FROM Produto pro JOIN ItemPedido ip ON ip.idPro = pro.idPro
WHERE ip.idPed <=3 ORDER BY ip.idPed;
Gabarito: B (Cabe recurso pela anulação da questão!)
O Auditor precisa criar uma view chamada PEDIDO1 com os dados do pedido 1 (id do item do pedido, id do produto, nome do produto, quantidade do produto no item e o preço unitário do produto). Se digitado o comando SELECT * FROM PEDIDO1; deverão ser exibidos os seguintes dados:
Para criar a View, o Auditor utilizou corretamente o comando
(A) CREATE VIEW PEDIDO1 AS SELECT ip.idItePed, ip.idPro, pro.nomePro, ip.qtdItePed, ro.PreUnitPro FROM Produto pro, ItemPedido ip WHERE ip.idPro = pro.idPro AND ip.idPed = 1;
(B) CREATE VIEW PEDIDO1 WITH SELECT ip.idItePed, ip.idPro, pro.nomePro, ip.qtdItePed, pro.PreUnitPro FROM Produto pro, ItemPedido ip WHERE ip.idPed = 1;
(C) CREATE VIEW PEDIDO1 AS SELECT ip.idItePed, ip.idPro, pro.nomePro, ip.qtdItePed, pro.PreUnitPro FROM Produto pro, ItemPedido ip WHERE ip.idPed = 1;
(D) CREATE VIEW PEDIDO1 ON SELECT ip.idItePed, ip.idPro, pro.nomePro, ip.qtdItePed, pro.PreUnitPro FROM Produto pro, ItemPedido ip WHERE ip.idPro = pro.idPro AND ip.idPed = 1;
(E) CREATE VIEW PEDIDO1 ON SELECT idItePed, idPro, nomePro, qtdItePed, PreUnitPro FROM Produto, ItemPedido WHERE ip.idPed = 1;
Comentário: Essa questão busca o conhecimento da sintaxe do comando para criação de uma visão. Sabemos que o comando é estruturado da seguinte forma: CREATE VIEW [NOME_DA_VIEW] AS SELECT …;
Assim, podemos eliminar as alternativas B, D e E. Agora precisamos escolher entre as alternativas A e C. Na alternativa A temos um erro na construção do comando, a ausência da letra ‘p’ no atributo pro.PreUnitPro. Isso ocasiona um erro na execução do comando e nenhuma linha será retornada como resposta ao comando. Já na alternativa C não temos o predicado “ip.idPro = pro.idPro”, isso mudaria a resposta observada pelo auditor.
A banca considerou como gabarito a alternativa A, contudo acredito que seja passível de recurso.
Gabarito: A (Cabe recurso pela anulação da questão!)
Para calcular o número de produtos com nomes que terminam com a letra B, o Auditor testou os comandos abaixo.
I. SELECT COUNT(nomePro) FROM Produto WHERE nomePro BEGIN ‘%B’;
II. SELECT COUNT(*) FROM PRODUTO WHERE SUBSTR(nomePro, -1)=’B’;
III. SELECT COUNT(*) FROM Produto WHERE nomePro LIKE ‘%B’;
IV. SELECT COUNT(nomePro) FROM Produto WHERE SUBSTR(nomePro, 0)=’B’;
Mostrará o resultado desejado o que consta APENAS em
(A) I e IV.
(B) III e IV.
(C) I e II.
(D) II e III.
(E) III.
Comentário: Mais uma vez o examinador explicita o uso do MySQL como banco de dados de teste dos comandos que aparecem na prova. Como eu falei ao longo das nossas aulas, o SQL ANSI é o padrão definido pela ISO/IEC. Por padrão SQL não usa SUBSTR, embora alguns SGBDs aceitem o comando. O comando correto seria SUBSTRING. Isso pode ser verificado no draft da norma neste link. Sendo assim, o único comando que funcionará em todos os SGBDs é o descrito no comando III. Assim a resposta correta deveria ser letra E e não D.
Gabarito: D (cabe recurso pela mudança de gabarito para E.)
Atenção: Para responder às questões de números 70 a 72, considere o seguinte caso hipotético:
Um Auditor da Receita Estadual pretende descobrir, após denúncia, elementos que possam caracterizar e fundamentar a possível existência de fraudes, tipificadas como sonegação tributária, que vêm ocorrendo sistematicamente na arrecadação do ICMS. A denúncia é que, frequentemente, caminhões das empresas Org1, Org2 e Org3 não são adequadamente fiscalizados nos postos de fronteiras. Inobservâncias de procedimentos podem ser avaliadas pelo curto período de permanência dos caminhões dessas empresas na operação de pesagem, em relação ao período médio registrado para demais caminhões.
Para caracterizar e fundamentar a existência de possíveis fraudes, o Auditor deverá coletar os registros diários dos postos por, pelo menos, 1 ano e elaborar demonstrativos para análises mensais, trimestrais e anuais.
70. O Auditor poderá fazer análises de pesagens diversas a partir de operações feitas sobre o cubo de dados multidimensional do Data Warehouse, por exemplo, trocar a ordem, ou aumentar ou diminuir a granularidade dos dados em análise, entre outras, como é o caso do uso da operação OLAP
(A) drill accross, que permite ao Auditor mudar o escopo de análise das informações de pesagens, filtrando e rearranjando determinadas partes do cubo de dados.
(B) roll out, que permite ao Auditor diminuir o nível de detalhe de análise das informações de pesagens.
(C) drill down, que permite ao Auditor aumentar o nível de detalhe de análise das informações de pesagens.
(D) drill off, que permite ao Auditor mudar o foco dimensional de análise das informações de pesagens.
(E) pivot, que permite ao Auditor pular um intervalo dimensional de análise das informações de pesagens.
Comentário: Veja que para navegar pela hierarquia das dimensões o Auditor deve usar as operações de drill down e roll up. Desta forma, podemos observar a resposta correta na letra C.
Gabarito: C.
A aplicação de técnicas de mineração de dados (data mining) pode ser de grande valia para o Auditor. No caso das pesagens, por exemplo, uma ação típica de mining, que é passível de ser tomada com o auxílio de instrumentos preditivos, é
(A) realizar uma abordagem surpresa em determinado posto, com probabilidade significativa de constatar ocorrência fraudulenta.
(B) reportar ao escalão superior as características gerais das pesagens e permanências de todos os caminhões, nos cinco maiores postos do Estado, no mês que antecede a data de análise.
(C) quantificar as ocorrências de possíveis pesagens fraudulentas ocorridas durante todo o trimestre que antecede a data da análise, em alguns postos selecionados, mediante parâmetros comparativos preestabelecidos.
(D) analisar o percentual de ocorrências das menores permanências de caminhões nos postos, no último ano, em relação ao movimento total.
(E) relacionar os postos onde ocorreram, nos últimos seis meses, as menores permanências das empresas suspeitas e informar o escalão superior para a tomada de decisão.
Comentário: O detalhe desta questão é a existência de uma análise preditiva. Toda análise preditiva carrega consigo um grau de incerteza. Logo, observamos na alternativa A a palavra chave probabilidade. Veja que estamos tentando determinar a hora certa para uma abordagem surpresa. As demais alternativa apresentam análises descritivas, algumas podem inclusive serem feitas sem a ajuda de mineração de dados, utilizando, por exemplo, ferramentas OLAP.
Gabarito: A.
Para permitir uma análise coerente, após a denúncia, a concepção de um modelo de dados multidimensional do tipo esquema estrela (star schema), em um Data Warehouse, deve registrar os elementos de dados: identificação do posto, empresa, data da pesagem e tempo de permanência. Considerando os conceitos fatos e dimensões, os elementos de dados classificados como dimensões são, apenas,
(A) identificação do posto, empresa e data da pesagem.
(B) empresa e data da pesagem.
(C) identificação do posto, data da pesagem e tempo de permanência.
(D) empresa, data da pesagem e tempo de permanência.
(E) identificação do posto e empresa.
Comentário: Pela teoria de modelagem dimensional sabemos que todo modelo deve ter uma dimensão data. Logo, a data da pesagem pode fazer esse papel. O posto e a empresas são outras entidades que participam do modelo como dimensões. Assim temos os 3 elementos de dados que podem ser classificados como dimensões. Já o item tempo de permanência pode ser visto como uma medida que aparece na tabela fato. Assim, temos nossa resposta na alternativa A.
Gabarito: A.
Existe uma correlação entre os modelos de documentos fiscais e os correspondentes registros da EFD-ICMS/IPI. Um registro “pai” C100 e seus respectivos “filhos”, que são gerados para escriturar apenas saída de produtos, deverão estar relacionados com o seguinte documento fiscal:
(A) Cupom fiscal, código 2D.
(B) Cupom fiscal eletrônico, código 60.
(C) Nota fiscal eletrônica para consumidor final, código 65.
(D) Nota fiscal de venda a consumidor, código 02.
(E) Nota fiscal avulsa, código 1B.
Comentário: Este registro, C100, deve ser gerado para cada documento fiscal código 01, 1B, 04, 55 e 65 (saída), conforme item 4.1.1 do Ato COTEPE/ICMS nº 09, de 18 de abril de 2008, registrando a entrada ou saída de produtos ou outras situações que envolvam a emissão dos documentos fiscais mencionados. As NFC-e – código 65 não devem ser escrituradas nas entradas. Logo, temos nossa resposta na alternativa C.
Gabarito: C
O arquivo digital EFD ICMS/IPI é constituído de blocos, cada qual com um registro de abertura, com registros de dados e com um registro de encerramento, referindo-se cada um deles a um agrupamento de documentos e de outras informações econômico-fiscais. O Bloco H tem por objetivo a reunião de informações relativas a
(A) apuração do Imposto sobre Operações Relativas à Circulação de Mercadorias e sobre Prestações de Serviços de Transporte Interestadual e Intermunicipal e de Comunicação (ICMS) e do Imposto sobre Produtos Industrializados (IPI).
(B) emissão ou recebimento de documentos fiscais referentes às entradas e saídas de mercadorias.
(C) abertura do arquivo, identificação das entidades, contabilistas e participantes e outras referências.
(D) divulgação do inventário físico do estabelecimento, nos casos e prazos previstos na legislação pertinente.
(E) emissão ou recebimento de documentos fiscais que acobertam as prestações de serviços de comunicação, transporte intermunicipal e interestadual.
Comentário: O bloco H destina-se a informar o inventário físico do estabelecimento, nos casos e prazos previstos na legislação pertinente. Logo, temos nossa resposta na alternativa D.
Gabarito: D
Considerando as informações I a IV relativas à
I. entrada e saída de mercadorias e aos serviços prestados e tomados, incluindo as descrições dos respectivos itens.
II. quantidade, descrição e valores de mercadorias, matérias-primas, produtos intermediários, materiais de embalagem, produtos manufaturados e produtos em fabricação, em posse ou pertencentes ao contribuinte.
III. produção de produtos em processo e produtos acabados, e respectivos consumos de insumos e ao estoque escriturado.
IV. qualquer situação de exceção na tributação, tais como isenção, imunidade, não-incidência, diferimento ou suspensão do recolhimento.
O arquivo digital da EFD-ICMS/IPI, referente a um período mensal declarado pelo contribuinte, ao ser transmitido deverá informar o que consta de
(A) II e III, apenas.
(B) II e IV, apenas.
(C) I, II, III e IV.
(D) I e III apenas.
(E) I, II e IV apenas.
Comentário: O arquivo digital da EFD-ICMS/IPI será gerado pelo contribuinte de acordo com as especificações do leiaute definido em Ato COTEPE e conterá a totalidade das informações econômico-fiscais e contábeis correspondentes ao período compreendido entre o primeiro e o último dia do mês civil, inclusive. Conforme consta no Ajuste SINIEF 02/09, fica dispensada a impressão dos livros fiscais. Considera-se totalidade das informações:
1 – as relativas às entradas e saídas de mercadorias bem como aos serviços prestados e tomados, incluindo a descrição dos itens de mercadorias, produtos e serviços.
2 – as relativas à quantidade, descrição e valores de mercadorias, matérias-primas, produtos intermediários, materiais de embalagem, produtos manufaturados e produtos em fabricação, em posse ou pertencentes ao estabelecimento do contribuinte declarante, ou fora do estabelecimento e em poder de terceiros e de terceiros de posse do informante;
3 – as relativas à produção de produtos em processo e produtos acabados e respectivos consumos de insumos, tanto no estabelecimento do contribuinte quanto em estabelecimento de terceiro, bem como o estoque escriturado;
4 – qualquer informação que repercuta no inventário físico e contábil, no processo produtivo, na apuração, no pagamento ou na cobrança de tributos de competência dos entes conveniados ou outras de interesse das administrações tributárias.
Qualquer situação de exceção na tributação do ICMS ou IPI, tais como isenção, imunidade, não-incidência, diferimento ou suspensão do recolhimento, também deverá ser informada no arquivo digital, indicando-se o respectivo dispositivo legal.
As informações deverão ser prestadas sob o enfoque do declarante. O contribuinte deverá armazenar o arquivo digital da EFD-ICMS/IPI transmitido, observando os requisitos de segurança, autenticidade, integridade e validade jurídica, pelo mesmo prazo estabelecido pela legislação para a guarda dos documentos fiscais.
Logo, observamos que todas as afirmações estão corretas e nossa resposta está na alternativa C.
Gabarito: C.
Os itens apresentados constituem uma lista em ordem alfabética de tarefas referentes ao arquivo digital da EFD-ICMS/IPI:
I. Assinar o arquivo por meio de certificado digital, tipo A1 ou A3, emitido por autoridade certificadora credenciada pela Infraestrutura de Chaves Públicas Brasileira (ICP-Brasil).
II. Gerar o arquivo de acordo com as especificações do leiaute definido em Ato COTEPE.
III. Gerar o recibo de entrega, com o mesmo nome do arquivo, com a extensão “rec”, gravando-o no mesmo diretório.
IV. Guardar o arquivo acompanhado do recibo da transmissão, pelo prazo previsto na legislação.
V. Submeter o arquivo ao programa validador, fornecido pelo Sistema Público de Escrituração Digital (SPED).
VI. Transmitir o arquivo, com a extensão “txt”, pela internet.
VII. Verificar a consistência das informações prestadas no arquivo.
Os procedimentos EFD-ICMS/IPI devem progredir em um fluxo de execução. Considerando que o item II refere-se à tarefa inicial e o item IV à tarefa final, a sequência intermediária correta do fluxo de execução é:
(A) VII − I − V − III e VI.
(B) VII − V − I − VI e III.
(C) I − V − VII − VI e III.
(D) V − I − VII − III e VI.
(E) V − VII − I − VI e III.
Comentário: O arquivo digital deve ser submetido a um programa validador, fornecido pelo SPED – Sistema Público de Escrituração Digital – por meio de download, o qual verifica a consistência das informações prestadas no arquivo. Após essas verificações, o arquivo digital é assinado por meio de certificado digital, tipo A1 ou A3, emitido por autoridade certificadora credenciada pela Infraestrutura de Chaves Públicas Brasileira – ICP-Brasil e transmitido. (V – VI – I)
A partir de 01 de janeiro de 2009, os contribuintes obrigados à Escrituração Fiscal Digital – EFD-ICMS/IPI devem escriturá-la e transmiti-la, via Internet em formato TXT. A obrigatoriedade da EFD-ICMS/IPI encontra-se na legislação estadual.
O contribuinte deve guardar a EFD-ICMS/IPI transmitida acompanhado do o recibo da transmissão, pelo prazo previsto na legislação. O recibo de entrega é gerado pelo ReceitaNet, com o mesmo nome do arquivo para entrega, com a extensão “REC” e será gravado sempre no mesmo diretório do arquivo transmitido. No arquivo do recibo, consta a identificação e também o “hash code” do arquivo transmitido.
Ordenando as ações descritas acima, podemos encontrar nossa resposta na alternativa E.
Gabarito: E
Com base no Schema XML: nfe_v99.99.xsd, a estrutura dos grupos de informações da NF-e apresenta o grupo “M – Tributos Incidentes no Produto ou Serviço” posicionado no mesmo nível de informações que o grupo
(A) “N − ICMS Normal e Substituição Tributária”.
(B) “W − Total da Nota Fiscal Eletrônica”.
(C) “C − Identificação do Emitente da Nota Fiscal Eletrônica”.
(D) “H − Detalhamento de Produtos e Serviços da Nota Fiscal Eletrônica”.
(E) “I − Produtos e Serviços da Nota Fiscal Eletrônica”.
Comentário: Se você lembrar da figura que usamos na nossa aula:
O grupo M está no mesmo nível do grupo I. Produto ou serviço da Nf-e. Logo, nossa resposta está na alternativa E.
Gabarito: E
Análises a partir de cruzamentos eletrônicos de informações permitem identificar divergências entre os arquivos XML da NF-e e os documentos escriturados da EFD-ICMS/IPI. Por exemplo, registros do grupo de informações “N − ICMS Normal e Substituição Tributária” podem ser extraídos do sistema de NF-e para serem comparados com registros de escrituração EFD-ICMS/IPI que estão gravados no bloco
(A) D.
(B) E.
(C) C.
(D) H.
(E) K.
Comentário: Questão tranquila, sabemos que o bloco E refere-se aos registros dos dados relativos à apuração do ICMS e do IPI.
Gabarito: B
NfeAutorizacao é um web service para disponibilizar o serviço destinado à recepção de mensagens de lote de NF-e. No caso do processamento assíncrono, as mensagens armazenadas na fila de entrada passam por validação de forma e das regras de negócios, e os resultados do processamento são armazenados na fila de saída. A validação da NF-e, não apresentando qualquer problema, resultará em “autorização de uso”, sendo a operação regular e a NF-e válida será armazenada no banco de dados. Caso ocorra algum problema de validação, o resultado poderá ser
(A) “rejeição”, sendo a operação regular e a NF-e válida gravada no banco de dados para ser corrigida.
(B) “rejeição”, sendo a operação irregular e a NF-e válida não gravada no banco de dados.
(C) “denegação de uso”, sendo a operação irregular e a NF-e válida não gravada no banco de dados.
(D) “denegação de uso”, sendo a operação irregular e a NF-e válida gravada no banco de dados.
(E) “rejeição”, sendo a operação irrelevante e a NF-e inválida gravada no banco de dados para ser corrigida.
Comentário: A validação da NF-e poderá resultar em:
Resumindo:
Assim, podemos marcar nossa resposta na alternativa D.
Gabarito: D
Sobre o processamento assíncrono das mensagens de solicitação de serviços realizado pela aplicação da NF-e a partir da fila de entrada de solicitações, considere:
I. o XML de cabeçalho é a Área de controle.
II. o XML de dados é a Área de mensagem.
III. o XML de cabeçalho contém o CNPJ do transmissor, o Número do recibo de entrega e a Data e hora de recebimento da mensagem.
IV. a Área de controle contém o CNPJ do transmissor, o Número do recibo de entrega e a Data e hora de recebimento da mensagem.
V. a Área de mensagem contém o XML de cabeçalho e o XML de dados.
Cada item da referida fila é formado por uma estrutura de armazenamento composta pelas informações que constam APENAS de
(A) II e IV.
(B) IV e V.
(C) I, II, III e IV.
(D) I e II.
(E) III e V.
Comentário: As filas de mensagens de solicitação de serviços são necessárias para a implementação do processamento assíncrono das solicitações de serviços. As mensagens de solicitações de serviços no processamento assíncrono são armazenadas em uma fila de entrada. Para ilustrar como as filas armazenam as informações, observe o diagrama a seguir:
A estrutura de um item é composta pela área de controle (identificador) e pela área de detalhe. As seguintes informações são adotadas como atributos de controle:
CNPJ do transmissor: CNPJ da empresa que enviou a mensagem que não necessita estar vinculado ao CNPJ do estabelecimento emissor da NF-e. Somente o transmissor da mensagem terá acesso ao resultado do processamento das mensagens de solicitação de serviços;
Recibo de entrega: Número sequencial único atribuído para a mensagem pela Secretaria de Fazenda Estadual. Este atributo identifica a mensagem de solicitação de serviços na fila de mensagens;
Data e hora de recebimento da mensagem: Data e hora local do instante de recebimento da mensagem atribuída pela Secretaria de Fazenda Estadual. Este atributo é importante como parâmetro de desempenho do sistema, eliminação de mensagens, adoção do regime de contingência, etc. O tempo médio de resposta é calculado com base neste atributo
Gabarito: B.
Qualquer dúvida estou às ordens,
Forte abraço!
Thiago Cavalcanti



As redes de ensino interessadas (estados, Distrito Federal e municípios) na Prova Nacional Docente (PND) deverão…
Acompanhe os editais dos Concursos Saúde previstos para os próximos meses Se você possui formação…
Se você está de olho em uma oportunidade no serviço público, o concurso Conab é…
Você é pedagogo? Saiba que o edital do concurso público da CONAB (Companhia Nacional de Abastecimento) oferta vagas…
O novo concurso público EsFCEx (Escola de Saúde e Formação Complementar do Exército) conta com a oferta…
Foi publicado o edital de concurso público da Prefeitura de Tremembé, município do estado de…









{kind=link}