Juliane Dionisio
Aprovada em 1° lugar no concurso TRT-10 para o cargo de Analista Judiciário - Especialidade: Arquivologia
Aprovada em 1° lugar no concurso TRT-10: Juliane Dionisio
Retomando a nossa série de temas sobre Ciência de Dados, área que despenca nas provas de Tecnologia da Informação e nas provas das carreiras mais concorridas, vamos apresentar hoje um resumo bem didático de R.
Por causa de sua característica interdisciplinar, a linguagem popularizou-se fortemente nos últimos anos e vem sendo explorada de forma sistemática pelas bancas. Em outras palavras, é uma aposta forte para as próximas provas de 2023.
Nós vamos falar do R de uma maneira mais objetiva e esquematizada. Será um artigo para você salvar nos favoritos para tirar dúvidas da linguagem e fazer revisões futuras. Assim, veja como os tópicos serão divididos:
O objetivo deste artigo não é ensinar você a programar de fato. Com efeito, o ideal é que você já tenha algum conhecimento prévio de linguagens de programação em geral para não ficar perdido.
No entanto, se ainda não conhecer absolutamente nada de linguagens de programação, a nossa sugestão é que você busque os materiais do Estratégia Concursos e retorne a esta publicação quando estiver preparado.
O artigo é indicado a todos os concurseiros que farão provas específicas da área de TI e/ou estudam para carreiras com nível de concorrência alto (Fiscal, Policial etc.).
Por fim, como esta publicação não será tão longa, a recomendação é que você faça a leitura de uma só vez. Como as seções são um pouco dependentes umas das outras, não é apropriado particionar o conteúdo. Bom, chega de papo. Vamos começar então?
Tempo de leitura aproximada: 15 a 20 minutos
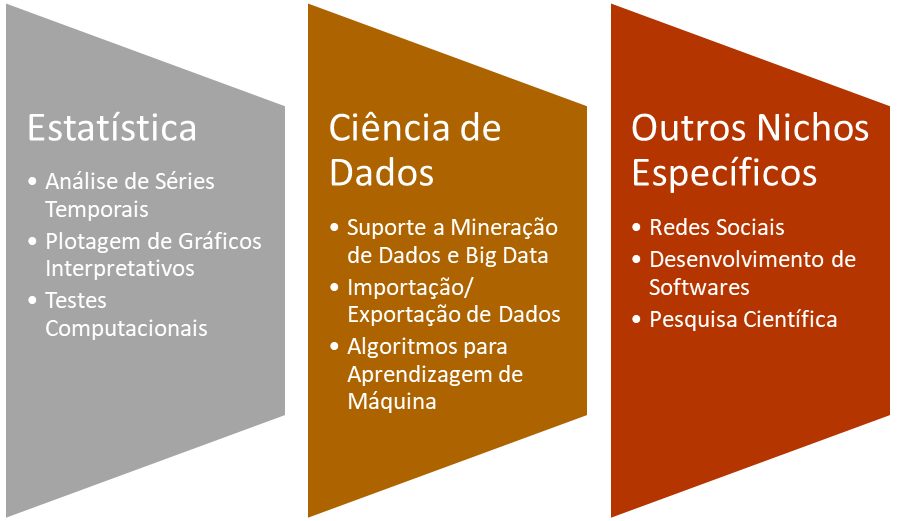
Primeiramente, R é aplicada no contexto de análise e exploração de dados. É uma linguagem não apenas utilizada pelos profissionais de TI, mas também por estatísticos e matemáticos que trabalham com Ciência de Dados.
Além disso, R possui diversas aplicações. Dessa forma, se você conhece um pouco de Python, pode achar que as linguagens fazem quase a mesma coisa. Veja no esquema abaixo o que esperar dela:
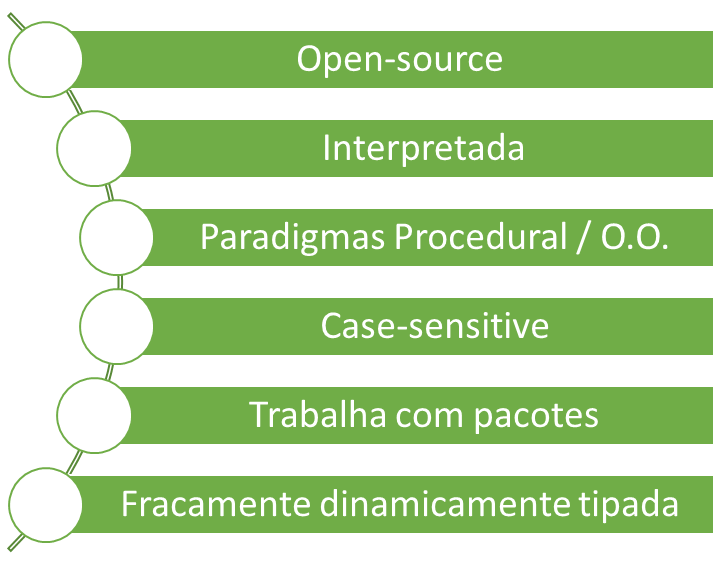
Antes de mais nada, R é uma linguagem aberta, que não requer o uso de licença para sua utilização (open-source). Em outras palavras, você não precisa pagar nada por ela. Possui compatibilidade com diversos sistemas operacionais, tais como Windows, Linux, Mac OS etc.
Em virtude de ser utilizada por profissionais que não são da área de TI, você pode presumir que R é uma linguagem simples, de fácil entendimento. Além disso, seu código é interpretado (não é compilado).
R contempla muitos pacotes e integrações com outras tecnologias para atender aos mais variados interesses. Embora haja muitas funções preinstaladas (R base, falaremos adiante), você talvez precise baixar pacotes adicionais para realizar o seu trabalho.
Por conseguinte, uma quantidade excessiva de instalações pode deixar o ambiente mais lento. Esse é um ponto negativo que pode ser apontado no uso da linguagem.
A respeito de paradigmas, R pode trabalhar com o imperativo/procedural, mais clássico, ou orientado a objetos, típico das linguagens recentes e mais difundido de uma forma geral. Ademais, R é uma linguagem case-sensitive (diferencia maiúsculas de minúsculas).
Por fim, R é considerada uma linguagem fracamente dinamicamente tipada. Ou seja, ela consegue entender o tipo da variável de forma dinâmica, durante a execução do programa, sem que o desenvolvedor defina previamente.
Como em toda linguagem, a sintaxe dos principais elementos é um pouco de “decoreba”. A fim de facilitar a sua vida, vamos apresentar em forma de quadro esquematizado.
Ressaltamos que R possui muitas formas diferentes de fazer a mesma coisa, tais como as impressões de saída. Quando isso ocorrer, vamos listar apenas as principais, de tal forma que o artigo não fique muito extenso:
| Elemento | Tipo | Representação |
|---|---|---|
| Comentário | # (em cada linha comentada) | |
| Entrada | Padrão | readLines( ) ou scan( ) |
| Arquivo | read.table( ) ou read.csv2( ) | |
| Saída | Padrão | print( ) ou paste( ) |
| Arquivo | write.table( ) | |
| Condicional | Se | if(expressão) { ações } else if(expressão) { ações } else { ações } |
| Escolha | switch(expressão, ação para caso 1, comando para caso 2, …, ação para caso n) | |
| Loop | Enquanto | while(expressão) { ações } |
| Para | for(variável in intervalo) { ações } | |
| Repetição (do-while) | repeat { ações if(expressão) { break } } | |
| Função | nome = function(parâmetros) { escopo } | |
| Tratamento de Exceção | tryCatch( expr = { expressão }, warning = function(parâmetros) { ações }, error = function(parâmetros) { ações }, finally = function(parâmetros) { ações }) |
Só para ilustrar, vamos apresentar um exemplo bem simples para você visualizar a sintaxe no código:
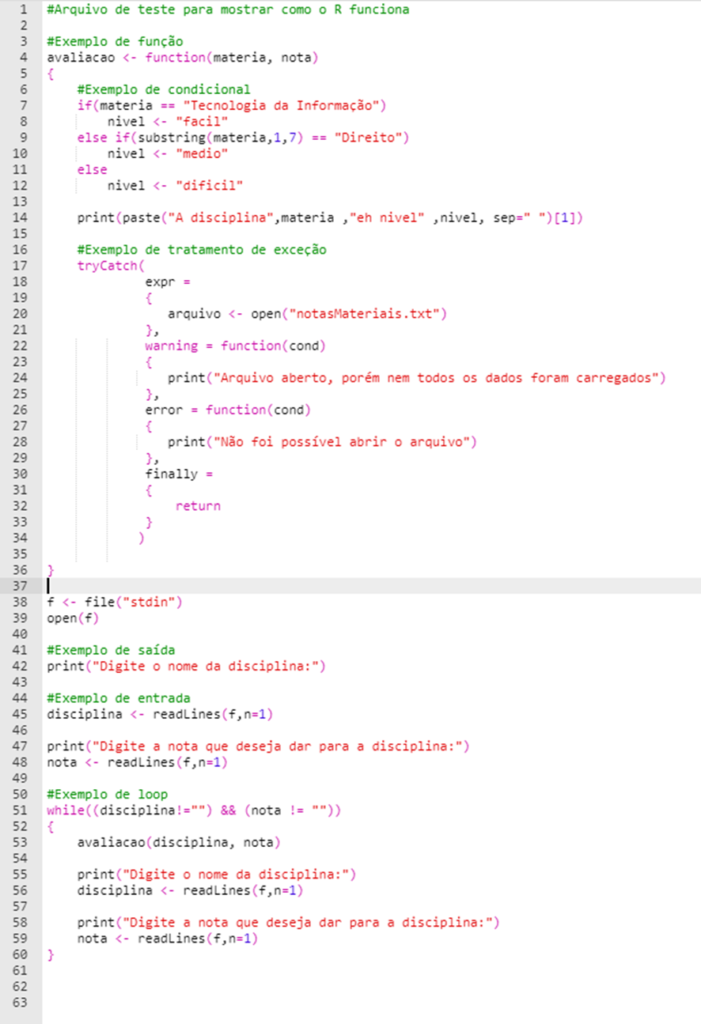
Muitas questões de R pedem para o candidato informar qual a saída esperada do programa. Sendo assim, é fundamental que você conheça a sintaxe da linguagem para conseguir resolvê-las.
Se você chegou até aqui e entendeu os conceitos apresentados, certamente já conseguirá acertar muitas questões. Nas próximas seções, vamos falar um pouco sobre outros aspectos do R que são muito explorados pelas bancas de concursos.
Não há muitos tipos de dados em R, se comparado a outras linguagens com que você deve estar acostumado. Dessa forma, segue um breve resumo esquematizado deles:
| Tipo | Descrição / Domínio | Exemplo |
|---|---|---|
| character | String de caracteres | “Estratégia Concursos” |
| complex | Números complexos | 2 + 5i |
| integer | Números inteiros | 37L (o L representa o tipo integer) |
| logical | Booleano (TRUE ou FALSE) | TRUE |
| numeric | Números reais em geral (ponto flutuante incluso) | 1.54 |
As principais estruturas de dados em R são vetores atômicos, listas, matrizes e data frames. Assim, vamos ver nesta seção um breve resumo esquematizado de cada um deles.
| Tipo | Descrição | Exemplo | Representação |
|---|---|---|---|
| Vetores Atômicos | Estruturas mais simples em R, cujos dados só podem ser de tipos primitivos. | c(1, 2, 3) | |
| Listas | Estruturas que admitem dados de qualquer tipo, incluindo listas. É possível misturar os tipos de dados na mesma lista. | list(“Cris”, 37L, 1.54, list(“Barra, RJ”) ) | 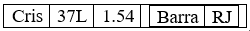 |
| Matrizes | Estruturas bidimensionais, com linhas e colunas. | matrix(1:8, nrow = 4, ncol = 2) | 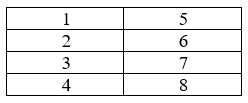 |
| Data Frames | Estruturas mais utilizadas em R, sendo uma mistura de listas e matrizes. Assemelham-se muito a uma tabela de banco de dados. | data.frame( id = c(1:3), nome = c(“Cristiane”, “Daniel”, “Paulo”), idade = c(37L, 41L, 70L) ) | 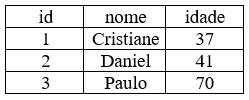 |
Coerção, no contexto de R, ocorre quando temos uma conversão de um tipo para outro em um vetor atômico. As conversões podem ocorrer automaticamente ou por meio de funções. Neste caso, chamamos de funções de coerção. Dessa forma, seguem as principais, juntamente com exemplos:
| Função de Coerção | Descrição | Exemplo | Resultado |
|---|---|---|---|
| as.character | Conversão para caracteres. | print(as.character(c(1,2,3))) | “1” “2” “3” |
| as.double | Conversão para ponto flutuante. | print(as.double(c(1, 2, 3))) | 1 2 3 |
| as.integer | Conversão para inteiro. | print(as.integer(c(“1.3”,”2.0”,”3.7”))) | 1 2 3 |
| as.logical | Conversão para booleano. | print(as.logical(c(0,1))) | FALSE TRUE |
| as.numeric | Conversão para número. | print(as.numeric(c(TRUE,FALSE))) | 1 0 |
Ressaltamos que as bancas não estão cobrando estruturas de dados a fundo (por exemplo, operações com seus elementos). Normalmente, as estruturas aparecem no meio de um código, a fim de que o candidato identifique o que fazem, a saída do programa etc.
Sendo assim, se você tiver entendido os exemplos e a forma de representação das estruturas, acreditamos que já será suficiente para acertar a maior parte das questões envolvendo esse tópico.
Ainda que R contemple inúmeras funções, as bancas não cobram todos os recursos da linguagem. A exigência maior é com as funções matemáticas e estatísticas, já que R é focado nessas áreas.
Ou seja, se você conhecer um pouco de funções em Excel, não terá grandes dificuldades para aprender funções matemáticas e estatísticas em R. Você verá que elas são muito parecidas. No entanto, se não conhecer nada, não desanime e fique conosco. Perceberá que é simples.
Assim, seguem as principais funções que caem nas provas, juntamente com seus exemplos, de uma forma esquematizada:
| Função | Descrição | Exemplo | Resultado |
|---|---|---|---|
| sum | Somatório | vetor <- c(1,2,3) print(sum(vetor)) | 6 |
| mean | Média | vetor <- c(1,2,3) print(mean(vetor)) | 2 |
| var | Variância | vetor <- c(1,2,3) print(var(vetor)) | 1 |
| summary | Resumo estatístico | vetor <- c(1,2,3) print(summary(vetor)) |  |
| quantile | Quartil | vetor <- c(1,2,3) print(quantile(vetor)) | 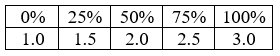 |
| plot | Geração de gráficos | plot(c(1,2),c(3,4)) | 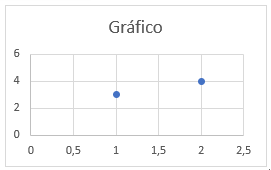 |
| getwd | Acesso à pasta para leitura dos arquivos de dados | print(getwd()) | “/home” |
| rev | Versão reversa dos objetos de dados | vetor <- c(1,2,3) print(rev(vetor)) | 3 2 1 |
| sort | Ordenação de valores | vetor <- c(3,1,2) print(sort(vetor)) | 1 2 3 |
A fim de clarificar a sua mente, o resumo estatístico apresenta os principais dados estatísticos do vetor, na seguinte ordem:
Momento Glossário: Quartil é a quarta parte (1/4) de um conjunto ordenado de valores. Em outras palavras, supondo que o conjunto representa 100% dos valores, cada quartil irá representar 25% do todo.

Como explicamos anteriormente, a linguagem R trabalha essencialmente com pacotes. As funções que já vem instaladas por padrão fazem parte de um ambiente básico, chamado R base.
No entanto, caso você necessite de alguma função adicional que não esteja no R base, será necessário recorrer a um dos pacotes. Como R é uma linguagem open-source, existem inúmeros pacotes em R, disponibilizados pela comunidade de desenvolvedores da linguagem.
Seria impossível e inútil para você falar sobre todos os pacotes existentes neste artigo. Por conseguinte, vamos focar nos pacotes que foram cobrados recentemente na prova do TCU e pegaram muita gente de surpresa: tibble e tidyr.
Este pacote é basicamente uma versão melhorada da estrutura data frames, que vimos nas seções anteriores. O objetivo é ajudar a trabalhar com os dados em formato de tabelas.
Exemplo: tibble (
nome = c(“Cristiane”, “Daniel”, “Paulo”),
idade = c(37L, 41L, 70L),
empresa = c(“Rioprevidência”, “Oi”, “Intracor”)
)
Veja que a função que cria o data frame tem o mesmo nome do pacote: tibble. Caso você não tenha importado o pacote, terá que referenciá-lo na chamada, da seguinte forma:
pessoa = tibble::tibble(conteúdo apresentado acima)
[pacote::função]
O data frame teria a seguinte estrutura. Estamos destacando os valores com cores diferentes apenas porque eles serão usados em outro exemplo e isso facilitará a nossa explicação futura:
| nome | idade | empresa |
|---|---|---|
| Cristiane | 37 | Rioprevidência |
| Daniel | 41 | Oi |
| Paulo | 70 | Intracor |
Teríamos outras coisas para falar sobre o tibble. No entanto, como mencionamos anteriormente, ainda não foram cobrados em prova.
Este pacote foca na transformação da base. Em outras palavras, suas funções podem alterar ou manipular um data frame já criado.
Exemplo: pessoa = tibble::tibble(
nome = c(“Cristiane”, “Daniel”, “Paulo”),
idade = c(37L, 41L, 70L),
empresa = c(“Rioprevidência”, “Oi”, “Intracor”)
)
tidyr::pivot_wider(
data = pessoa,
names_from = “nome”,
values_from = “idade”
)
Agora vamos explicar a fundo o nosso exemplo. A 1ª. parte você já conhece, pois copiamos do exemplo anterior. A função tibble vai criar o data frame com as colunas nome, idade e empresa.
Na 2ª. parte, vamos utilizar a função pivot_wider do pacote tidyr. Essa função vai alterar a estrutura do data frame pessoa (data = pessoa), da seguinte forma: os valores do campo nome passarão a ser nomes de colunas (names_from = “nome”).
Por outro lado, os valores da coluna idade serão valores das novas colunas, como se fossem células (values_from = “idade”). E quanto ao campo empresa? Como ele não foi mencionado no pivot_wider, não sofrerá alteração. Ou seja, ele continuará sendo uma coluna no data frame. Veja como ficou:
| empresa | Cristiane | Daniel | Paulo |
|---|---|---|---|
| Rioprevidência | 37 | NA | NA |
| Oi | NA | 41 | NA |
| Intracor | NA | NA | 70 |
De fato, veja que é como se o data frame tivesse sido pivotado mesmo. Um ponto importante é que você irá reparar que não temos dados em algumas células. Por exemplo, as colunas Daniel e Paulo estariam vazias na linha em que o “Rioprevidência” aparece, pois eles não trabalham lá.
A fim de solucionar este problema, o R utiliza o NA, que significa “não disponível” (not available, em inglês). A saber, é uma espécie de null que a linguagem entende.
A famosa questão do TCU atacou basicamente essas 2 funções que mencionamos. Em outras palavras, se você entendeu os pontos que explicamos nesta seção, será capaz de fazer a questão do TCU tranquilamente.
Em suma, apresentamos no artigo de hoje um resumo esquematizado da linguagem R, um tema que despenca nas provas de Tecnologia da Informação que exigem Ciência de Dados. Assim, se você leu o artigo na íntegra e entendeu bem os conceitos, o próximo passo agora será realizar muitas questões para treinar.
Alunos aprovados realizam centenas ou até milhares de questões para atingir seu objetivo. O acesso ao Sistema de Questões do Estratégia é feito pelo link: https://concursos.estrategia.com/.
Não esqueça também de retornar ao tópico periodicamente para fazer revisões. Este artigo foi preparado especialmente para ajudar você nisso. Salve-o nos seus favoritos e utilize-o da melhor forma.
Por fim, se você quiser aprofundar o conteúdo ou tirar dúvidas específicas da linguagem, busque o material do Estratégia Concursos. Nós oferecemos diversos cursos em pdf, videoaulas e áudios para você ouvir onde quiser.
Bons estudos e até a próxima!
Cristiane Selem Ferreira Neves é Bacharel em Ciência da Computação e Mestre em Sistemas de Informação pela Universidade Federal do Rio de Janeiro (UFRJ), além de possuir a certificação Project Management Profissional pelo Project Management Institute (PMI). Já foi aprovada nos seguintes concursos: ITERJ (2012), DATAPREV (2012), VALEC (2012), Rioprevidência (2012/2013), TJ-RJ (2022) e TCE-RJ (2022). Atualmente exerce o cargo efetivo de Especialista em Previdência Social – Ciência da Computação no Rioprevidência, além de ser colaboradora do Blog do Estratégia Concursos.